Sentence Similarity
Sentence Similarity allows you to compare the semantic similarity between two or more sentences. It’s especially useful in applications such as content recommendation, plagiarism detection, or customer feedback analysis, where understanding the meaning between texts is crucial.
This simple tutorial shows how you can run a sentence similarity task on NuPIC. It consists of 5 sentences and computes a similarity score between each pair.
Quick Start
Before you start, make sure the NuPIC Inference Server is up and running, and the Python environment is set up.
Navigate to the directory containing the sentence similarity example:
cd nupic.examples/examples/simple_sentence_similarityOpen simply_sentence_similarity.py using a text editor, ensure that the URL points to the NuPIC inference server, and that the embedding model of your choice is correctly defined. In the example code below, we assume the Inference Server is running on the same machine as the Python Client:
URL = "localhost:8000"
PROTOCOL = "http"
MODEL = "nupic-sbert.base-v3"
CERTIFICATES = {}The command below will run a Python script that asks the NuPIC Inference Server to compute pairwise similarity scores between the five sentences:
python simply_sentence_similarity.py| # | Sentences |
|---|---|
| 1 | "A man with a hard hat is dancing." |
| 2 | "A man wearing a hard hat is dancing." |
| 3 | "My father has a banana pie." |
| 4 | "My mother has cooked an apple pie." |
| 5 | "The answer to the life, the universe and everything." |
The server will return the most similar sentences and scores:
Results Analysis:
--------------------------------------------------------------------------------
Original sentence: "A man with a hard hat is dancing."
Most similar sentence: "A man wearing a hard hat is dancing."
Similarity score: 0.991
--------------------------------------------------------------------------------
Original sentence: "A man wearing a hard hat is dancing."
Most similar sentence: "A man with a hard hat is dancing."
Similarity score: 0.991
--------------------------------------------------------------------------------
Original sentence: "My father has a bannana pie."
Most similar sentence: "My mother has cooked an apple pie."
Similarity score: 0.471
--------------------------------------------------------------------------------
Original sentence: "My mother has cooked an apple pie."
Most similar sentence: "My father has a bannana pie."
Similarity score: 0.471
--------------------------------------------------------------------------------
Original sentence: "The answer to the life, the universe and everything."
Most similar sentence: "My father has a bannana pie."
Similarity score: 0.085
--------------------------------------------------------------------------------In More Detail
What is simple_sentence_similarity.py doing under the hood? Using NuPIC BERT models, each input sentence is converted into a numerical embedding vector.
# init client, with protocol, url and model to use
client = ClientFactory.get_client(MODEL, URL, PROTOCOL, CERTIFICATES)
# encode the strings
encodings = client.infer(sentences)["encodings"]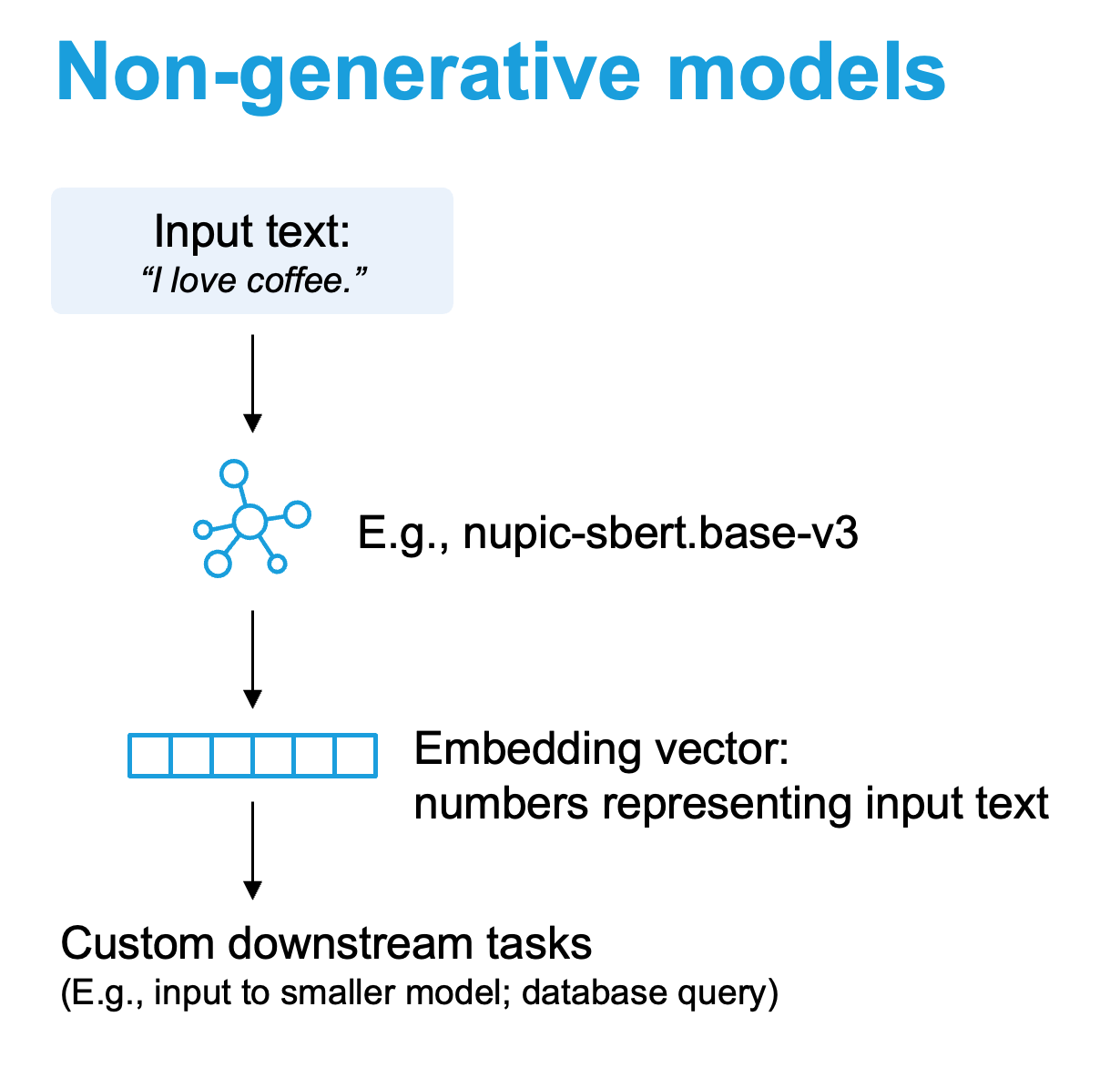
The similarity between these embeddings is calculated using cosine similarity. The similarity score will always be between -1 and 1, where 1 means the sentences are identical, and -1 means they are completely dissimilar.
# computes cosine similarity
dot_products = encodings @ encodings.T
norms = np.sqrt(np.diag(dot_products))[:, np.newaxis]
cosine_similarities = dot_products / norms / norms.TUpdated 7 days ago