GPT Output Streaming
GPT models are often deployed in use-cases requiring real-time user interactions, such as chatbots or virtual assistants. In such situations, perceived latency is a critical part of a user's experience. Nobody wants to wait too long for a GPT model to respond!
Output streaming is a feature that allows models to print their responses as they are being generated. This prevents the user from having to wait for a complete response to be generated, thereby improving the perceived latency.
Quick Start
Before you start, make sure the NuPIC Inference Server is up and running, and the Python environment is set up.
Navigate to the directory containing the GPT streaming example:
cd nupic.examples/examples/streamingThe example assumes we are calling the Inference Server from a local client. If you are running the example from the remote client, please adjust the URLs in run.sh and streaming.py, and remember to use the --expose flag when starting the Inference Server.
Now make run.sh executable, and proceed to run it:
chmod +x run.sh
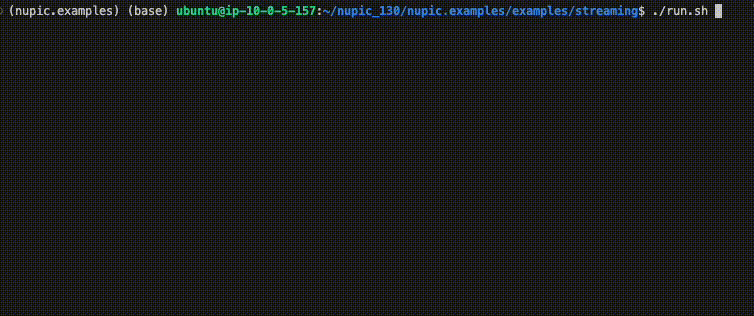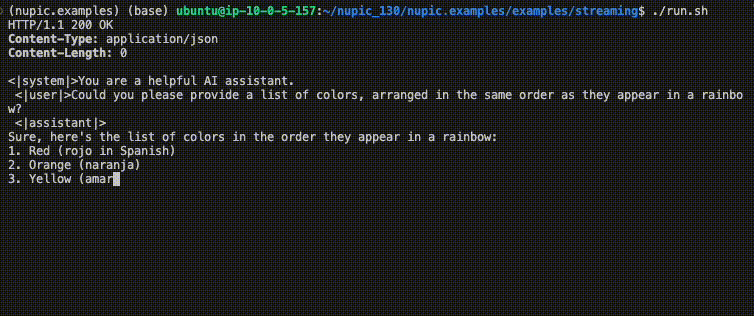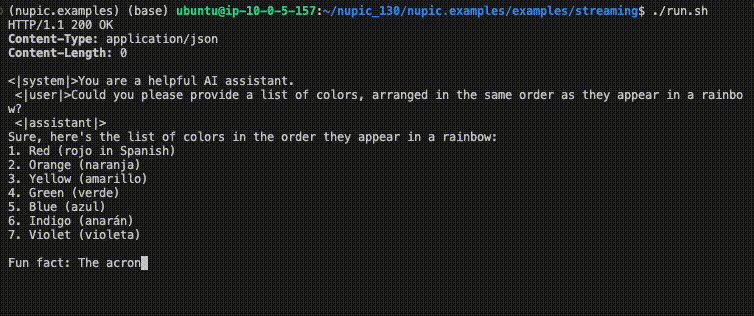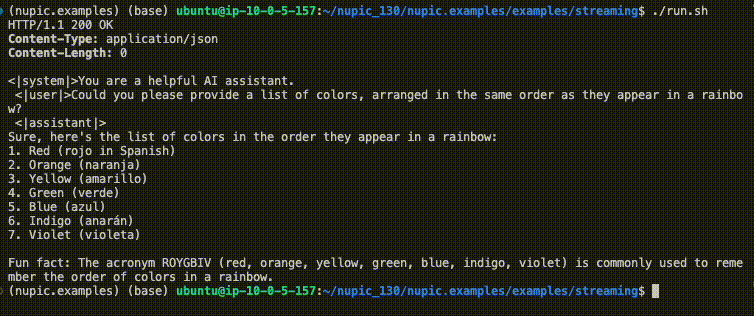
./run.shYou should see something similar to the GIF in the introduction to this page.
In More Detail
run.sh is a thin wrapper that calls streaming.py in the same page. Let's examine the latter in a text editor:
from nupic.client.inference_client import StreamingClient
from nupic.client.utils import get_prompt_formatter, model_naming_mapping
...
def callback(text):
print(text, end="", flush=True)
def main():
model_name = model_naming_mapping[model_name]
...
# Create the streaming client
client = StreamingClient(model_name, url="localhost:8001")
# Generate a streaming response
client.generate(prompt, callback=callback)
...There are a few noteworthy concepts here. Let's step through them one at a time.
First, notice the use of a simple callback function (line 4 in the snippet above) that prints any text that is passed to it. This gets called each time the model generates a token (line 16).
Next, we have to use a GPT model version that supports output streaming. This is indicated by the ".streaming" suffix in the model name.
Finally, output streaming requires a client-server connection using the GRPC protocol instead of REST. We can tell from the fact that we are connecting to the port 8001, which is the default GRPC port on the Inference Server.
Updated 7 days ago