BERT Throughput
We now know NuPIC BERT models run much more quickly on CPU, but there are more aspects to performance than just inference time. Specifically, we could look at throughput (queries per second) and latency (seconds per query).
In this tutorial, we focus on running a throughput benchmark to understand how the Inference Serve can help you support requests from a large pool of users. By experimenting with the number of simulated users and varying input lengths, we'll help you to understand the following questions:
- What are the differences in throughput between the unoptimized BERT base model and optimized NuPIC BERT models?
- What happens to throughput when we send longer text inputs to the models?
- What happens to throughput when we have many users?
- What is the relationship between throughput and latency?
We'll answer these questions by randomly sampling texts from a financial sentiment dataset, passing them as inputs to both unoptimized and NuPIC BERT models.
Quick Start
Before you start, make sure the NuPIC Inference Server is running, and the Python client/environment is set up.
We begin by navigating to the relevant subdirectory within your nupic/ folder:
cd nupic.examples/examples/throughput_testLet's open throughput.py in a text editor to look at some configurations:
N_CLIENTS = [1, 2, 4]
SEQ_LENS = [64, 128]
URL = "localhost:8000"
MODELS = [
"bert.base-wotokenizer",
"nupic-sbert.large-v1-wotokenizer",
"nupic-sbert.base-v3-wotokenizer",
]By default, the script will simulate 1, 2 and 4 users (aka clients) who are all trying to send requests to the inference server at the same time. We will also simulate scenarios in which users are sending inputs of different sequence lengths (defaults are 64 and 128).
For simplicity, we assume the Inference Server is hosted locally, but you can edit the URL if you have a remote setup.
Here we want to compare three models: the unoptimized bert.base model, and the optimized nupic-sbert.large-v1 and nupic-sbert.base-v3 models. You may recall that nupic-sbert.base-v3 is a smaller version of nupic-sbert.large-v1.
Since we are interested in measuring model throughput, we are measuring the models without their tokenizers, so as to avoid any overheads. Instead, tokenization is performed on the client side.
Alright, let's get started with the experiment. We're simulating many scenarios, so this may take a while.
python throughput_test.pyExpected output:
Running 18 Tests:
Test 1:
-------
Model : bert.base-wotokenizer
Num Clients : 1
Seq length : 64
...When it's done, results are logged to results.csv in the same directory. If you want to visualise these results, use the provided Jupyter notebook analysis.ipynb.
In More Detail
For your convenience, we've already ran the experiments on a wider range of clients and sequence lengths. Note that we used a larger number of clients (16, 32, 64 and 128) in order to depict a high-traffic scenario where the inference server is severely overloaded. With this setup, we'll highlight some trends to address the questions introduced earlier.
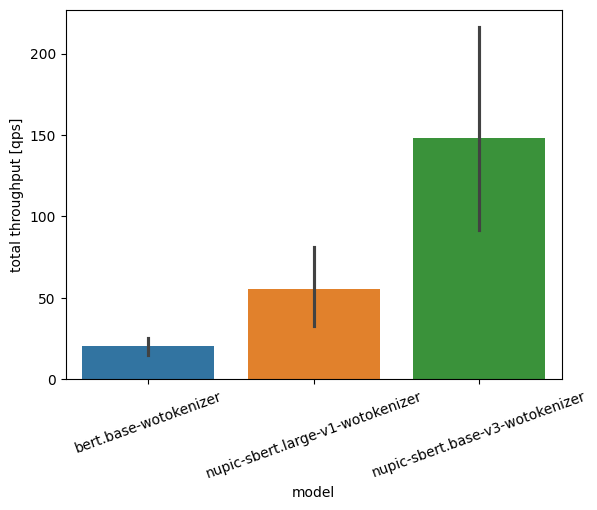
Looking at the diagram below, in terms of total throughput, nupic-sbert.large-v1 and nupic-sbert.base-v3 can serve approximately 2x and 7x more requests than hf-bert.base-1-v0. But let's dig a little deeper.
In the next diagram, we focus on the experience of each user. We see that all models show decreasing throughput when users send longer texts, as expected. This means that if each user needs to send multiple requests at once, the inference server can process them faster if each request is shorter.
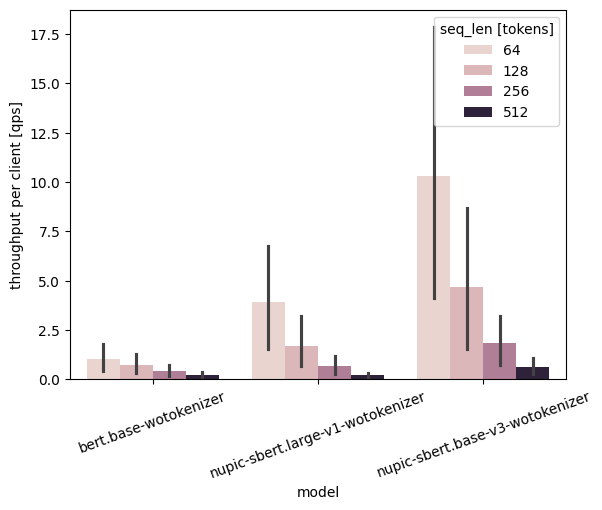
What's particularly interesting is that for a given sequence length, NuPIC models are always able to serve more requests per client per second. Moreover, nupic-sbert-base-v3 (the lightweight model) with a input length of 512 is able to almost match the performance of bert.base running with a much shorter input length of 64! What this tells us is that in the challenging scenario of having to server simultaneous requests from each client, each with long input lengths, NuPIC models are the way to go.
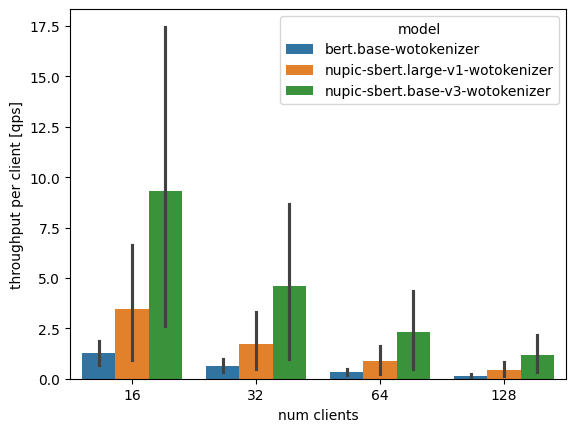
In our third diagram, we look at what happens when there are many users trying to access your model at the same time. For all models, throughput suffers when we have to serve more clients. But again, note that nupic-sbert.base-v3 shows about the same throughput with 128 clients as bert.base serving just 16 clients!
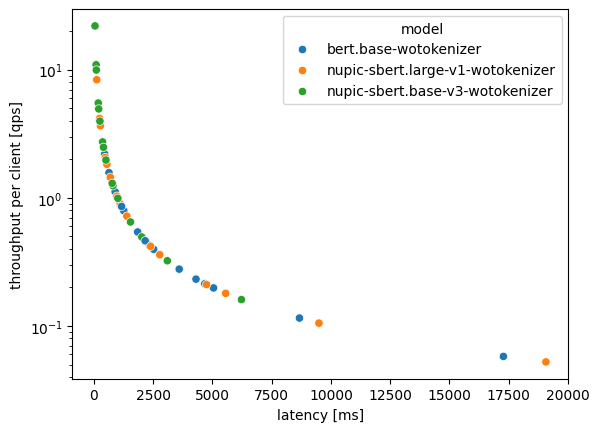
Lastly, we see that throughput and latency have a negative relationship. Generally, if you need high throughput, you'll have to trade off latency and vice-verse. In the digram, data points with high latency depict scenarios with a large number of clients and/or sequence length. What's important to note there is that data points from NuPIC BERT models tend towards the upper left of the graph (high throughput, low latency), while the regular BERT model tends towards the lower right (low throughput, high latency). So while we still can't have our cake and eat it, NuPIC is about as good as it gets. To further tune NuPIC to trade-off between throughput and latency, you can refer to our guide here.
So what's the TLDR? Compared to unoptimized BERT models, NuPIC BERT models running on our Inference Server generally give higher throughput, and this continues to be true under challenging conditions of longer input lengths and many simultaneous clients. This means NuPIC BERT models are an excellent choice to ensure your users get a good experience even under the most challenging workloads at scale.
Updated 7 days ago