Recommendation System
Recommendation systems are useful for suggesting new content to a user of your platform. Familiar examples include the systems powering your YouTube and Netflix feeds.
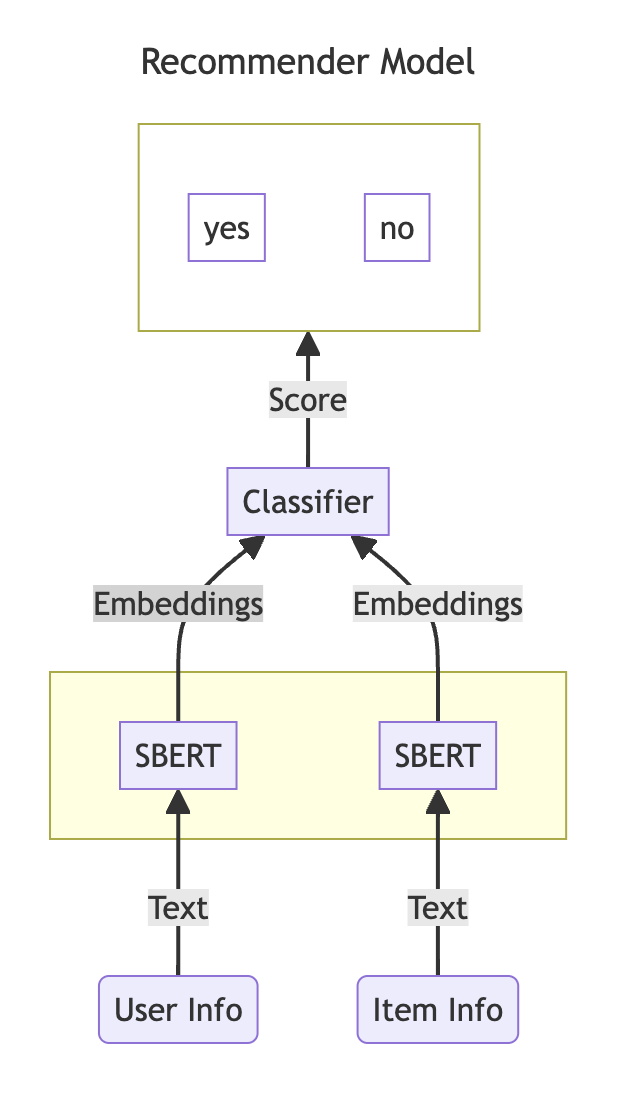
In this example, we use a NuPIC SBERT model as part of a Two-Tower recommender architecture, where left tower encodes user features and the right tower encodes item features. We will encode the article textual information using NuPIC SBERT and classify the resulting embeddings into a recommendation score that tells us whether to recommend an item to a user.
Quick Start
Before you start, make sure the NuPIC Inference Server is running, and the Python client/environment is set up.
For simplicity and clarity, this page assumes the Inference Server and Python clients are running on the same machine.
We begin by navigating to the recommender example:
cd nupic.examples/examples/recommenderLet's download some data to train our recommender. We will use the MIND dataset (Wu et al., ACL 2020), which was collected from anonymized behavior logs of the Microsoft News website. Before using the dataset, please make sure you agree with the Microsoft Research License Terms. Running the following Python script will download and prepare the data.
python data/mind.pyOnce done, your data directory should look like this. Note the newly written parquet files containing the processed data.
nupic.examples/examples/recommender/data/
├── MINDdemo_dev/
├── MINDdemo_train/
├── MINDdemo_utils/
├── mind_dev_demo.parquet # test data
├── mind_train_demo.parquet # train data
├── mind.py
└── utils.pyTo train the recommender, we can run train.py by passing flags that point it to the parquet files we just generated.
python train.py \
--train-data data/mind_train_demo.parquet \
--test-data data/mind_dev_demo.parquet Once done, your deploy/ folder should look like this:
nupic.examples/examples/recommender/deploy/
├── recommender-score
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
└── recommender-wtokenizer
├── 1
└── config.pbtxtTo deploy the trained recommender, let's copy the trained model to the inference server:
cp -r deploy/recommender-score <your-nupic-dir>/inference/models
cp -r deploy/recommender-wtokenizer <your-nupic-dir>/inference/modelsNow you can run the inference script to match users to the content on your platform. This produces recommendation scores for all possible user-item pairs, and returns the top K candidates.
python inference.py --recommendation_size 5 \
--item-data content_data.parquet \
--user-data user_data.parquet Example output:
===============================================================================
User: (T-800, 'Cyberdyne Systems|Director of Special Projects|Management')
===============================================================================
content_id item score
30 4375244 Lorem ipsum dolor sit amet, consectetur elit 0.006172
31 4372304 Urna condimentum mattis pellentesque id nibh tort 0.006134
32 4362984 Erat imperdiet sed euismod nisi porta lorem molli 0.005959
33 4375564 Lacinia quis vel eros donec ac odio tempor orci 0.005931
34 4370604 A scelerisque purus semper eget duis at tellus. 0.005858In More Detail
Data Preparation
Examining the diagram at the start of this page, you might notice that the Two-Tower recommender is essentially a binary classifier. For a given user-item pair, the user can either be interested or uninterested in the article. To train the model, we can map these to positive and negative labels respectively.
However we'll need to prepare the data with these labels. We can get positive labels by extracting examples where a given user had clicked on the item. On the other hand, we might have a class imbalance problem if we naively took all examples where the same user had not clicked on the item as negative labels.
To understand this, let's consider this scenario. Suppose you watched 50 YouTube videos in the past week. How many videos out of YouTube's entire collection did you not watch? If we took the naive approach to negative labeling, that'd be millions of negative labels, against just 50 positive labels. Most AI/ML algorithms don't train well with such a massively imbalanced distribution of class labels.
To address, this, we want to sample just a subset of a possible negative examples. The data/utils.py module provides a ratio argument to help you specify the ratio of negative to positive examples for training:
def build_user_item_pairs(
data: pd.DataFrame,
user_id_col: str,
user_info_cols: list[str],
item_info_cols: list[str],
ratio: int = 4,
progress: bool = True,
):
"""
Build labeled dataset composed of item pairs and a boolean label indicating
whether or not the item represents a positive or negative impression. The
negative impressions are sampled from all the other items not selected by
the same user.
:param data: Data composed items selected/click by user
:param ratio: Ratio between negative to positive impressions
:param user_id_col: user id column index
:param user_info_cols: List of columns containing the user information.
i.e. ["job_title", "company_name", ...]
:param item_info_cols: List of columns containing the item information
i.e. ["headline"]
:param progress: Whether or not to show progress bar
:return: Dataframe with the follwoing columns:
["label", "user_text", "item_text"]
"""In addition, the user_info_cols and item_info_cols arguments help you select the user and item features you want to include for training the model to predict positive/negative labels.
Embeddings
The user and item features contain textual information that we want to convert to vector embeddings, which we can then use to train the downstream classifier. We can do so using non-generative BERT-style models in the NuPIC Model Library. User and item features are sent to your choice of BERT-style model running on the Inference Server, which returns the corresponding embeddings.
We need a large number of pairwise examples to train our recommender. For instance, we need labeled examples of User 1's interactions with Item A, Item B and Item C. Similarly, we also need labeled examples of User 2's interactions with Item A, Item B and Item C. We can speed up the embedding process by leveraging the fact that these pairwise examples tend to be repetitive (see how Items A-C are repeated for the two users). To do so, we want to turn on response caching on our BERT model of choice. We can do so it the respective config.pbtxt file within the <your-nupic-dir>/inference/models/<your-bert-model>:
name: "nupic-sbert.base-v3-wotokenizer"
platform: "onnxruntime_onnx"
model_operations { op_library_filename: "/models/libcajalonnx.so" }
model_repository_agents { agents [{name: "cajal"}] }
response_cache { enable: true } <---You'll also want to make sure that response caching is enabled on the Inference Server:
./<your-nupic-dir>/nupic_inference.sh start --enable-cachingWith these enabled, the Inference Server no longer needs to compute repetitive entries from scratch, and the embedding process can happen a lot more quickly.
Training the Classifier
As previously mentioned, we want to train a binary classifier using the embedding vectors we just generated. However, this is not the same as training the BERT model itself—we are only training the classifier component located downstream of the BERT model (see diagram at the top of this page). That's why we don't need to use the Training Module in this example. In fact, training takes place on the client side. The BERT weights on the server side stay frozen.
In the example code train.py passes instructions through several wrappers to the simple MLP classifier at model.py. You can see in the latter script that the MLP is quite small, with just two linear layers and a single output node corresponding to the binary response we need.
class RecommenderModel(nn.Module):
"""
Simple MLP Classifier used to classify User/Item embeddings into a
recommendation score
"""
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.LazyLinear(128),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(128, 128),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(128, 1),
)The reason the MLP can be so small is because much of the heavy lifting (converting user and item features to a numerical representation) was already performed by the BERT model on the server side. In fact, you might wish to explore using an even simpler model, such as a logistic regression or random forest classifier.
Evaluation Metrics
To keep things simple, the example returns precision, recall and F1 scores. In the recommendation context, here are the interpretations:
- Precision: Given that the model returns a positive recommendation, what are the chances that the user is actually interested in the item?
- Recall: Given an item that we know that the user is in fact interested in, what are the chances that our model correctly recommends it to the user?
- F1: A balanced combination of precision and recall.
From a business/platform point of view, it would be advantageous to prioritize recall so that we don't "miss out" on an items that the user might want to interact with. But naively prioritizing recall alone will bombard the user with a massive number of items that they probably aren't interested in (false positives), leading to an unpleasant user experience. So in practice it's important to balance both precision and recall—that's why we have F1!
Updated 7 days ago