RAG with LangChain
This example demonstrates the use of Retrieval Agumented Generation (RAG) pipelines via LangChain integrations on the NuPIC Python client to answer questions based on document retrieval and generative models. Before diving into this page, you may find it useful to first understand how NuPIC works with LangChain for both generative and non-generative models.
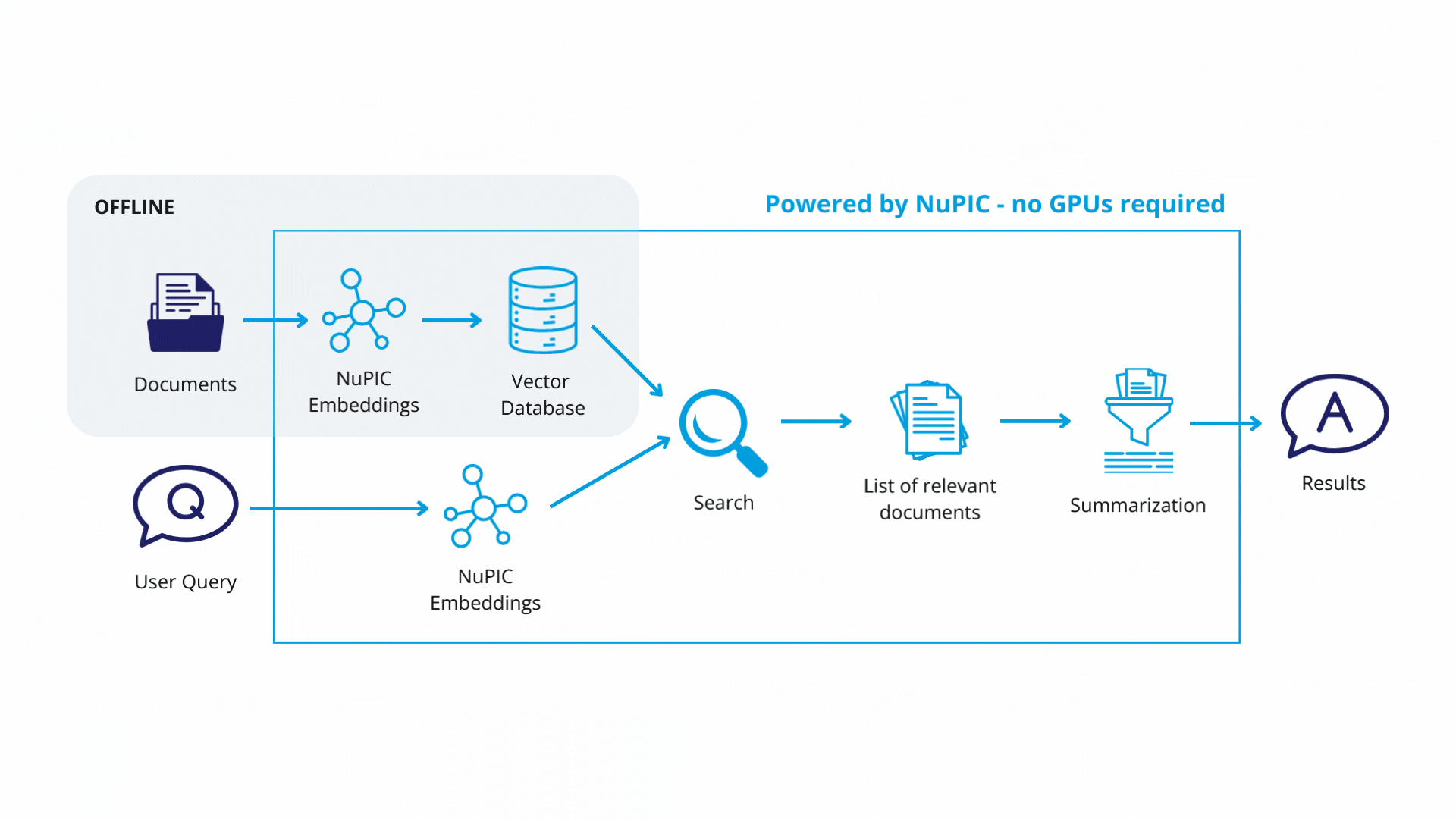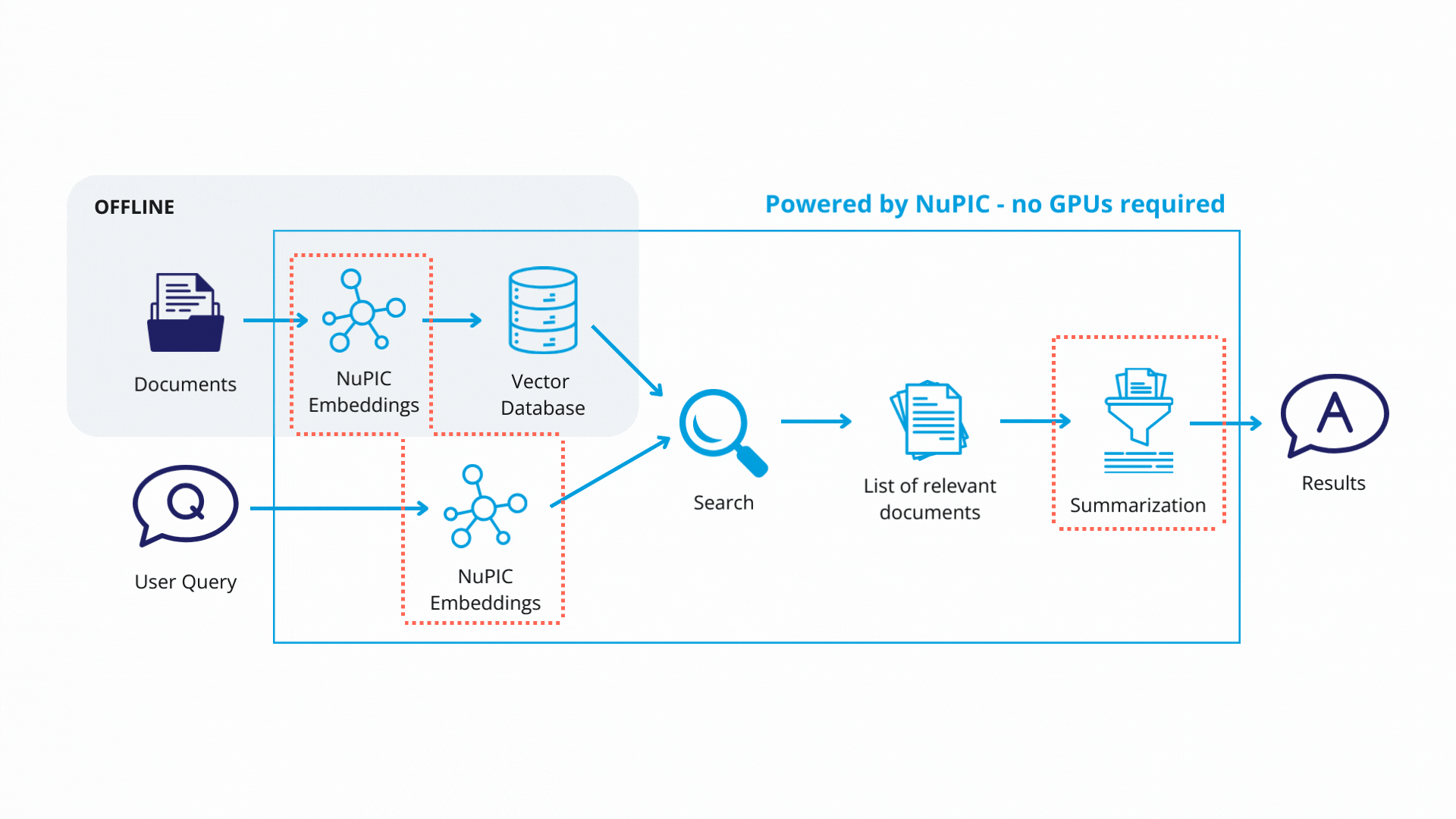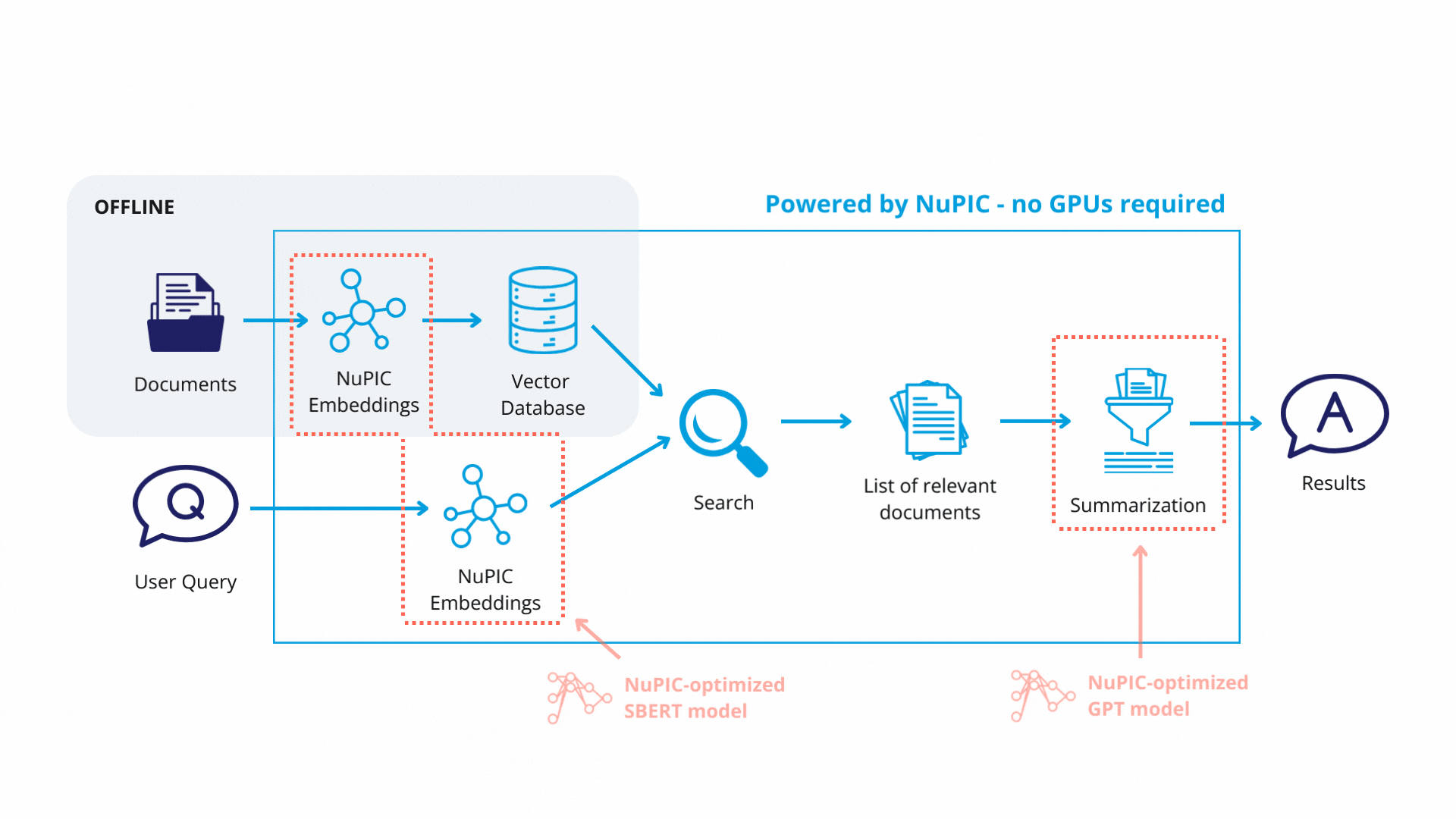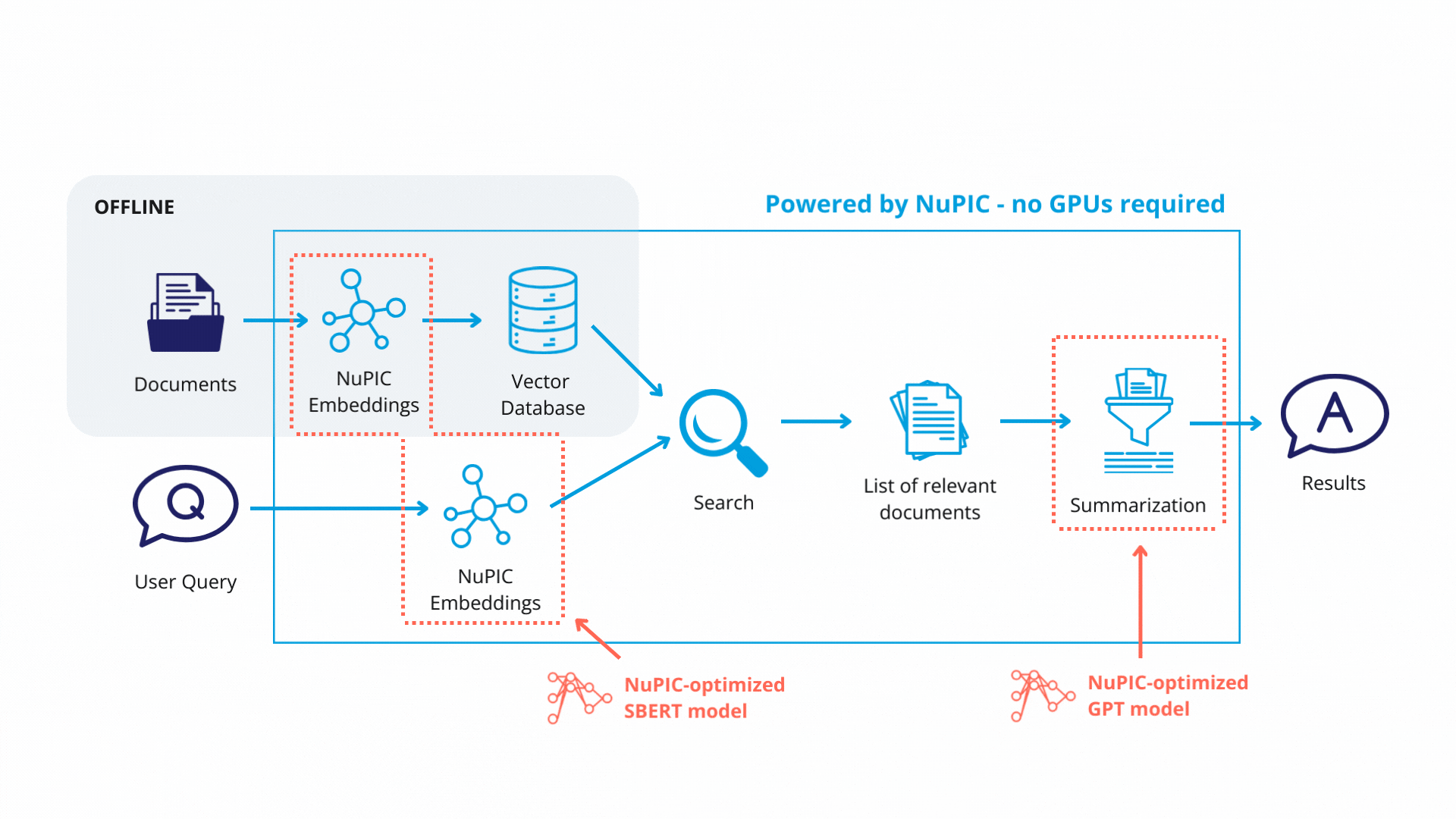
Quick Start
Before you start, make sure the NuPIC Inference Server is up and running, the Python environment is set up, and the example data is downloaded.
- Installation Guide
- Set up Python Environment
- Download our Thousand Brains Theory paper. Ensure it is named
s42452-021-04715-0.pdf.
We begin by navigating to the folder containing LangChain example:
cd nupic.examples/examples/langchain
Place s42452-021-04715-0.pdf within the datasets/ folder.
Then, open rag_example.py using a text editor, and ensure that the Inference Server URL, embedding model and GPT model are correctly specified. The code below assumes the Inference Server is running locally together with the Python client. A quick way to get started is to use the pre-installed NuPIC-GPT model.
embeddings = NuPICEmbedding(
url="localhost:8000",
model="nupic-sbert.large-v1",
)
,,,
model = "nupic-gpt"
long_model_name = model_naming_mapping[model]
prompt_formatter = get_prompt_formatter(long_model_name)
Now we are ready to run the Python script!
python rag_example.py
Your output should look like this:
Question: Why are Sparse distributed representations (SDRs) an important part of the Thousand Brains theory?
Assistant: Sparse distributed representations (SDRs) are an important part of the Thousand Brains theory because they allow for efficient representation and processing of large amounts of data, which is crucial for understanding the complex and dynamic environments that humans and animals interact with. In the neocortex, SDRs are created by neurons operating on hierarchically organized representations known as columns. These representations are generated by integrating inputs from many different sources, including sensory inputs as well as feedback and modulatory signals from other brain regions. The sparsity of these representations, meaning that only a small subset of neurons in a column become active in response to a particular input, allows for efficient representation of a large number of different inputs without overlap or redundancy. Furthermore, the ability of neurons to perform computations on SDRs through dendritic operations, rather than just at the axon terminals, allows for further efficiency and integration of information. Overall, the use of SDRs and column-based organization is a fundamental aspect of the Thousand Brains Theory, as it provides a biological framework for understanding complex computational processes in the brain.
In More Detail
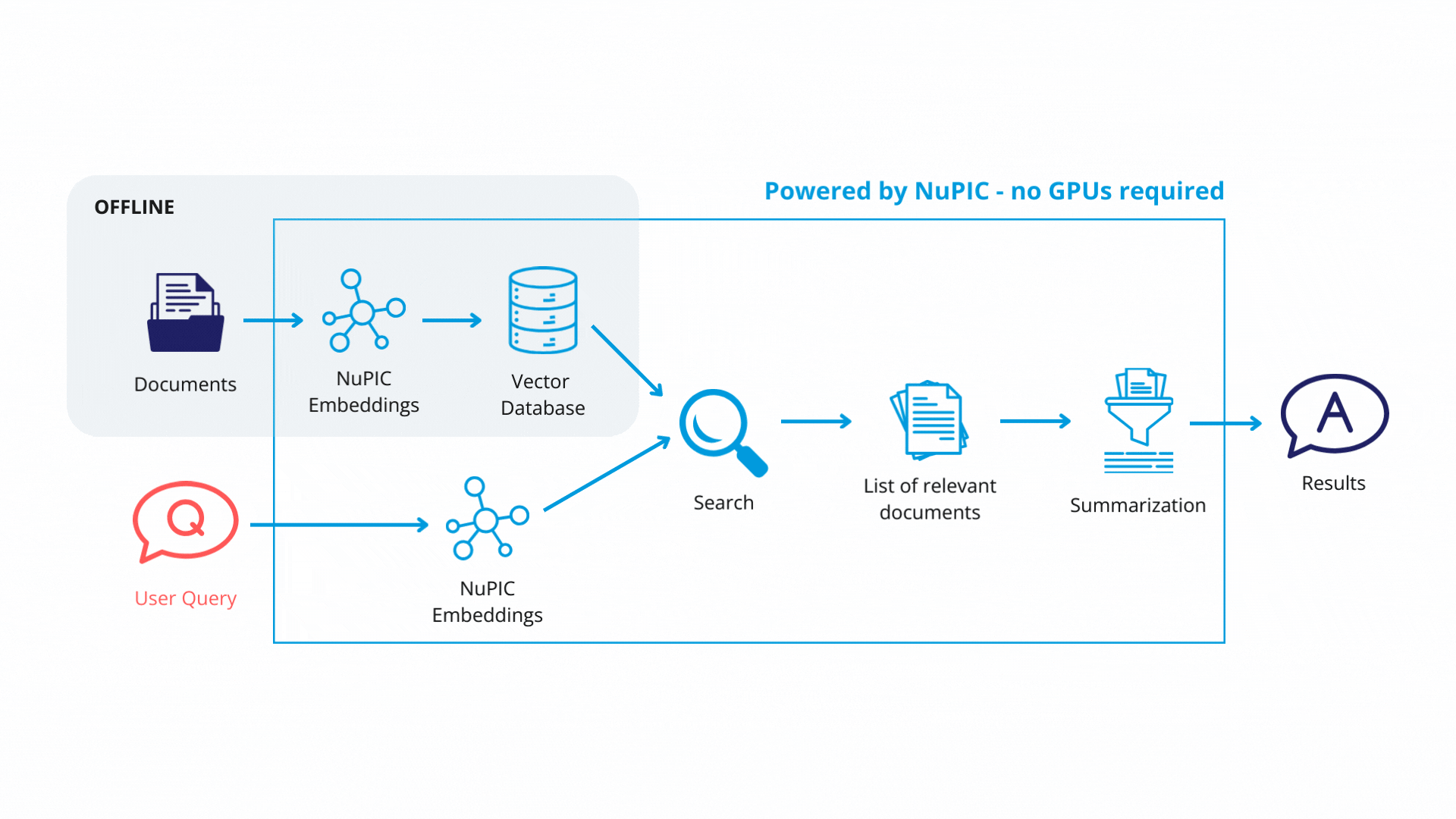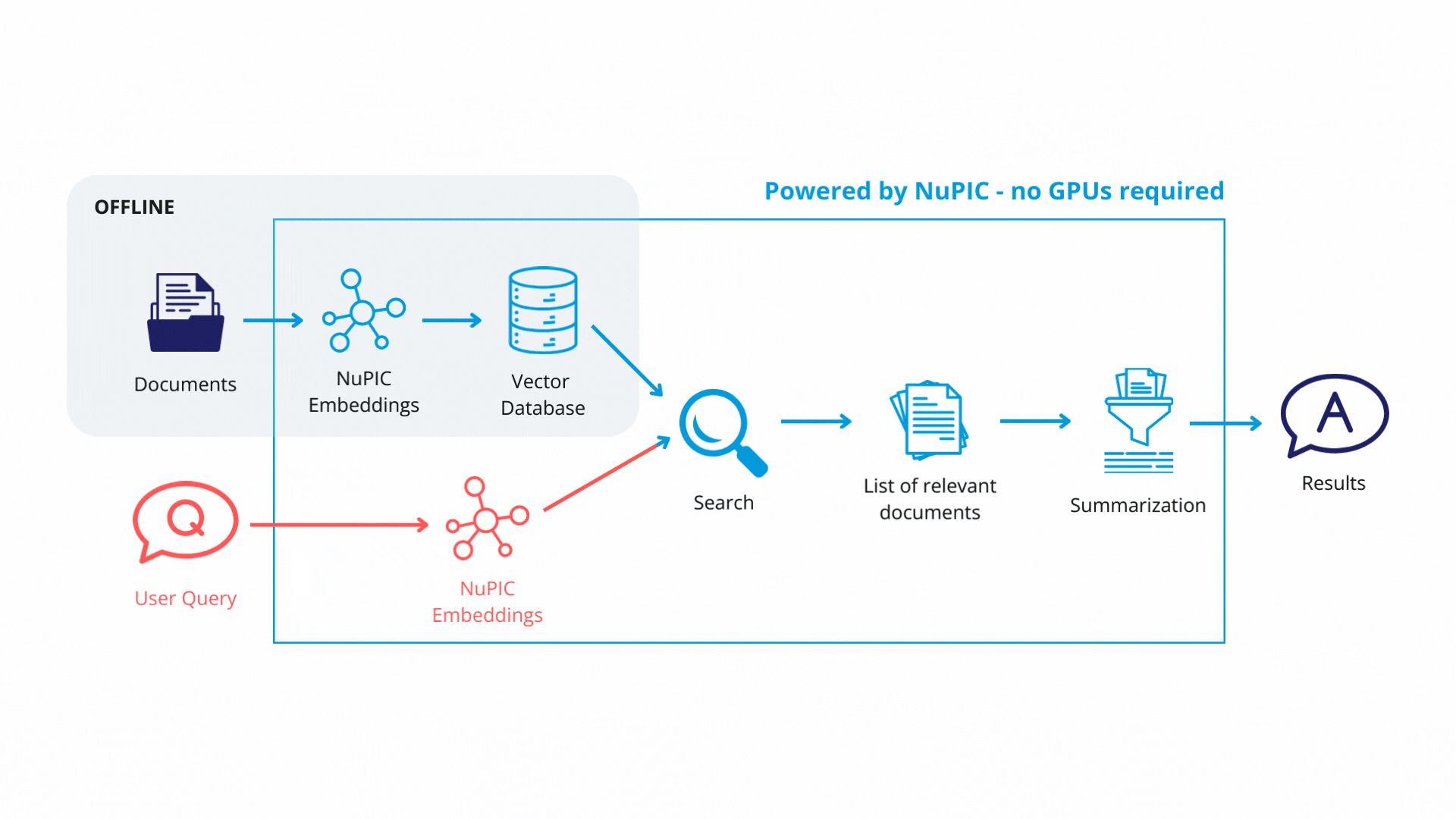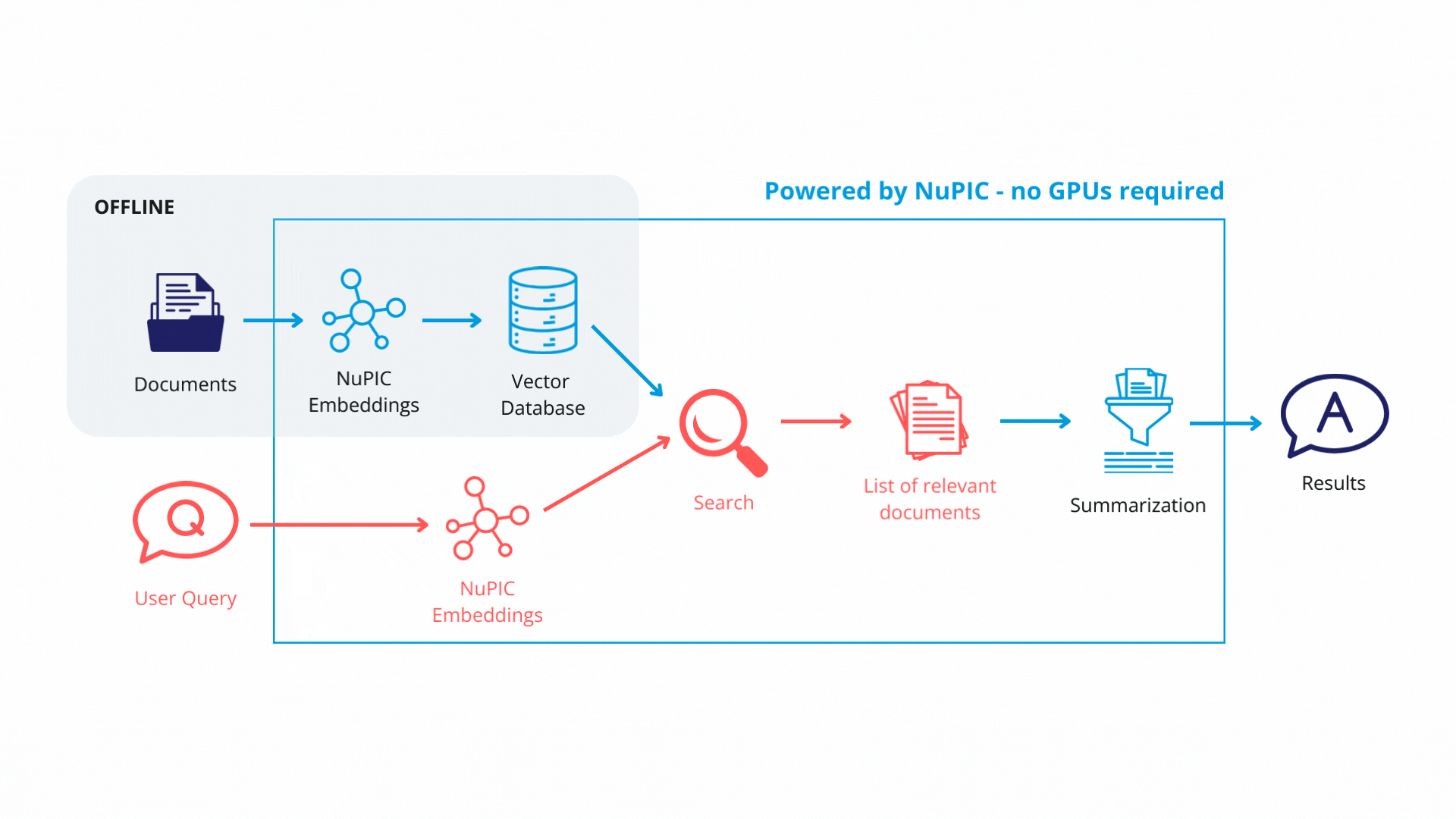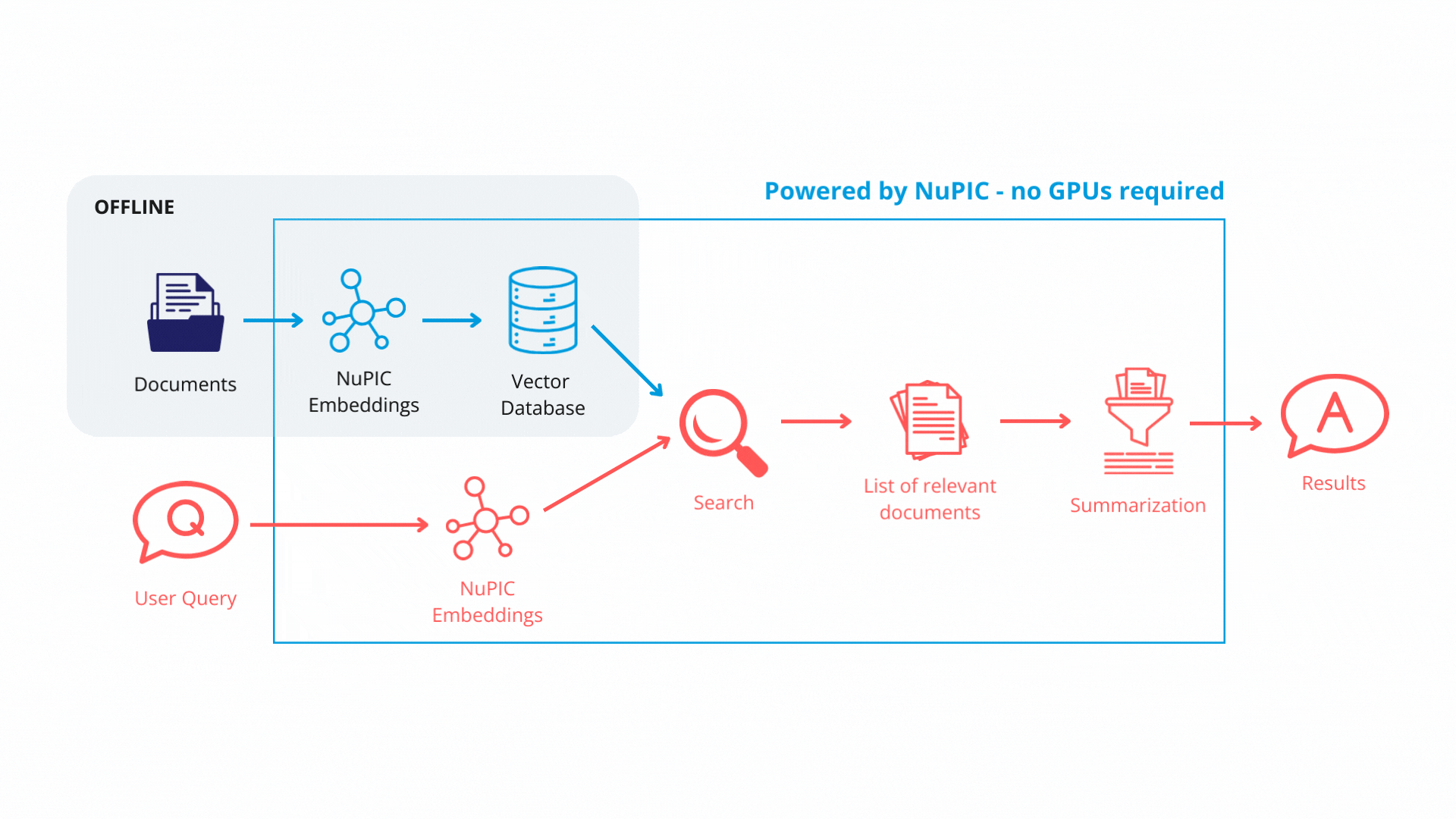
Let's look at how rag_example.py works. We start by splitting the PDF document into small chunks so that each chunk can fit within the input size limits of the subsequent embedding model:
texts = loader.load_and_split(
RecursiveCharacterTextSplitter(chunk_size=512 * 3, chunk_overlap=128 * 3)
)
Each text chunk is then passed to a NuPIC embedding model (wrapped with a LangChain class) that produces embedding vectors encoding the meaning of each chunk. The vectors and their corresponding chunks are then stored as key-value pairs, respectively, in a vector database. In production, you will only need to update the vector database when you modify or add new documents.
vectorstore = Chroma.from_texts(texts=chunks, embedding=embeddings)
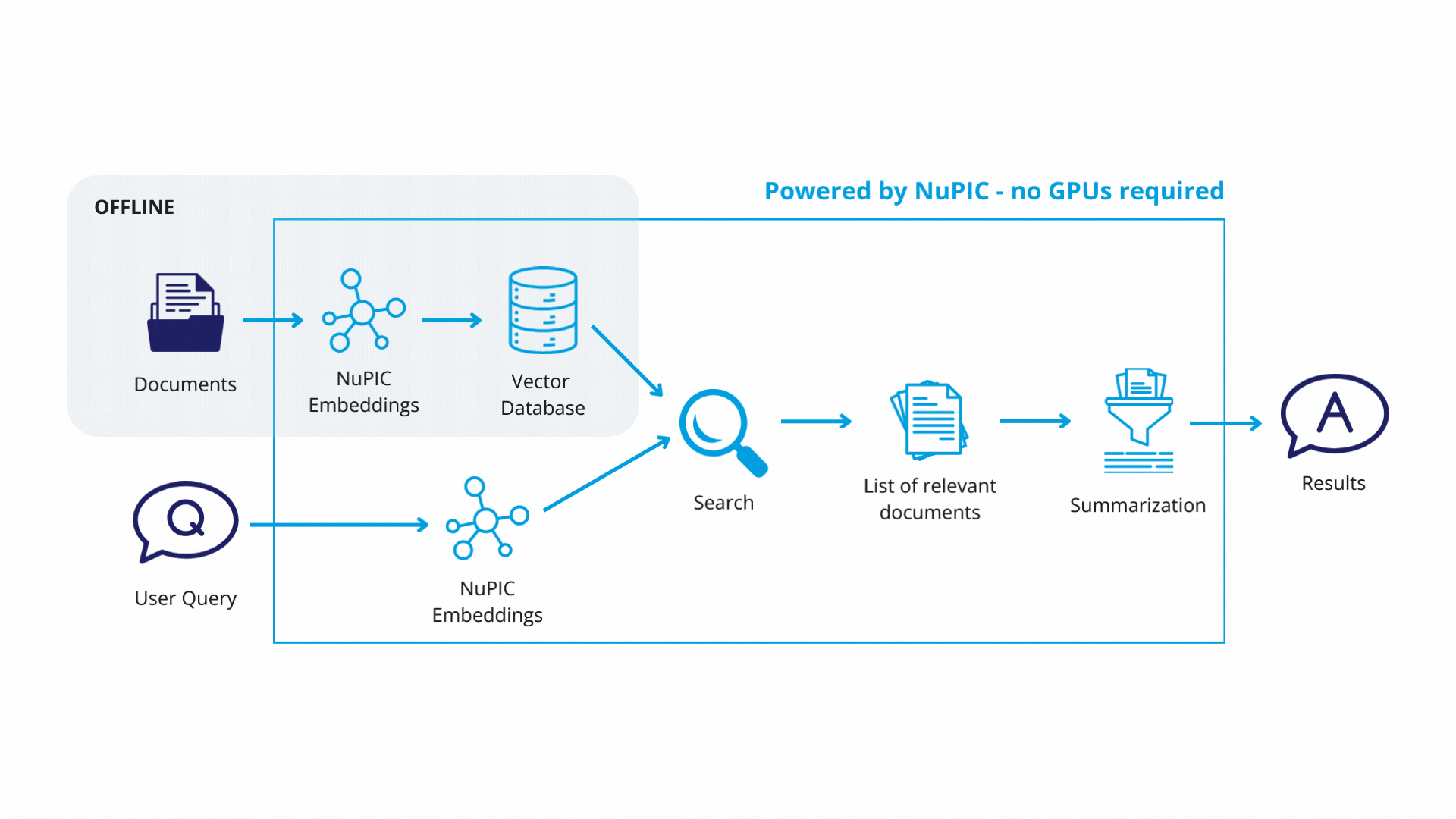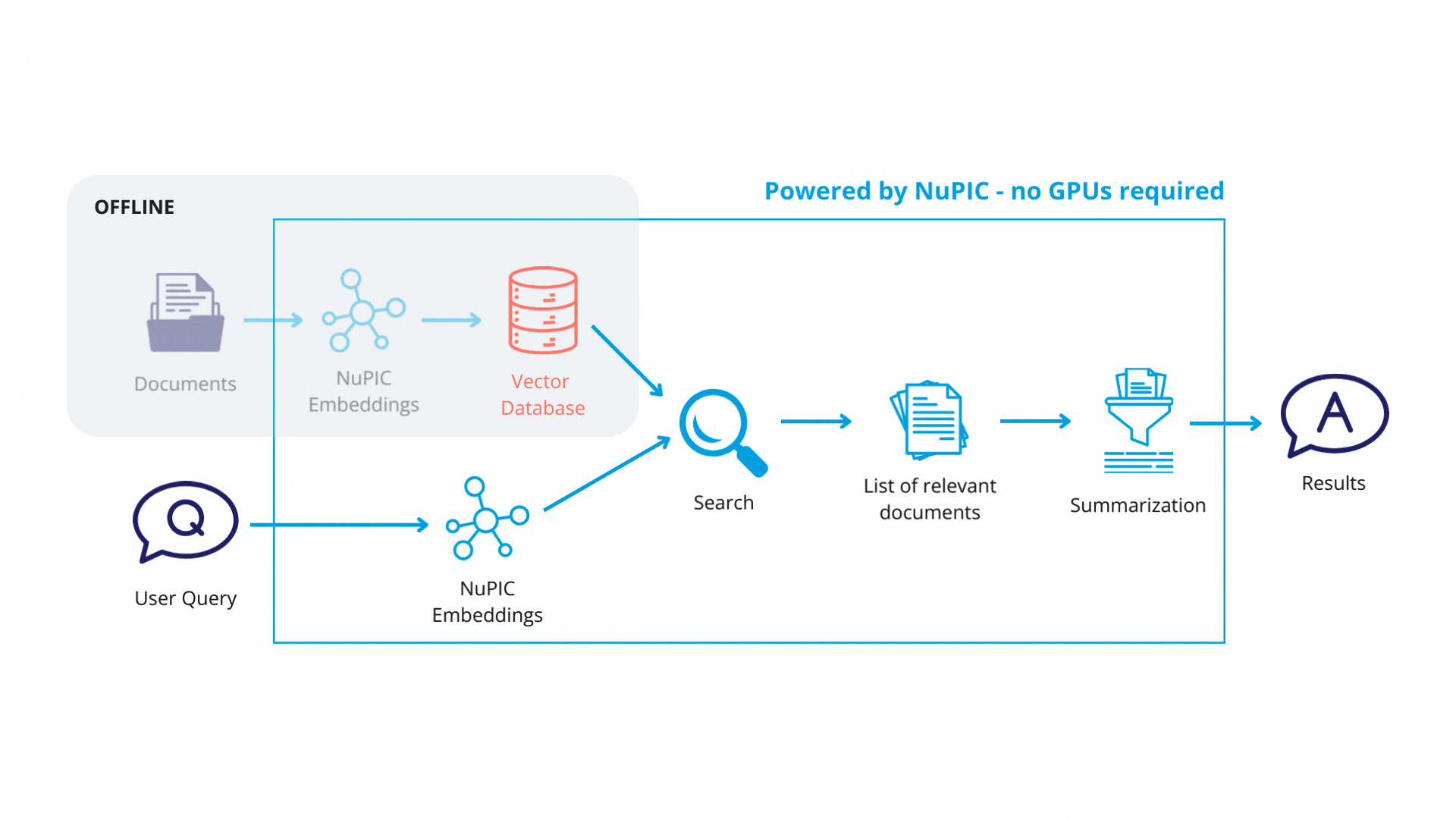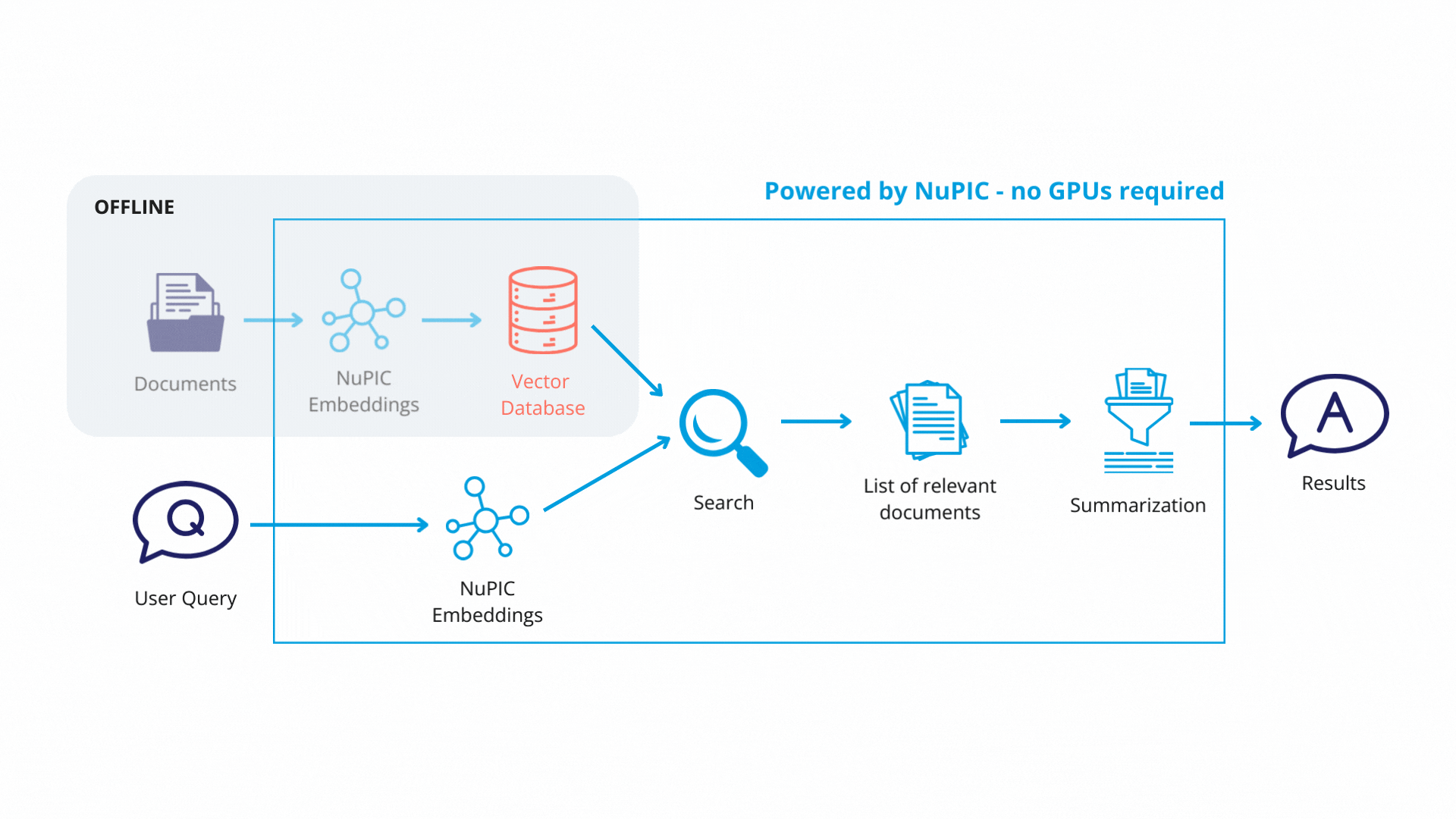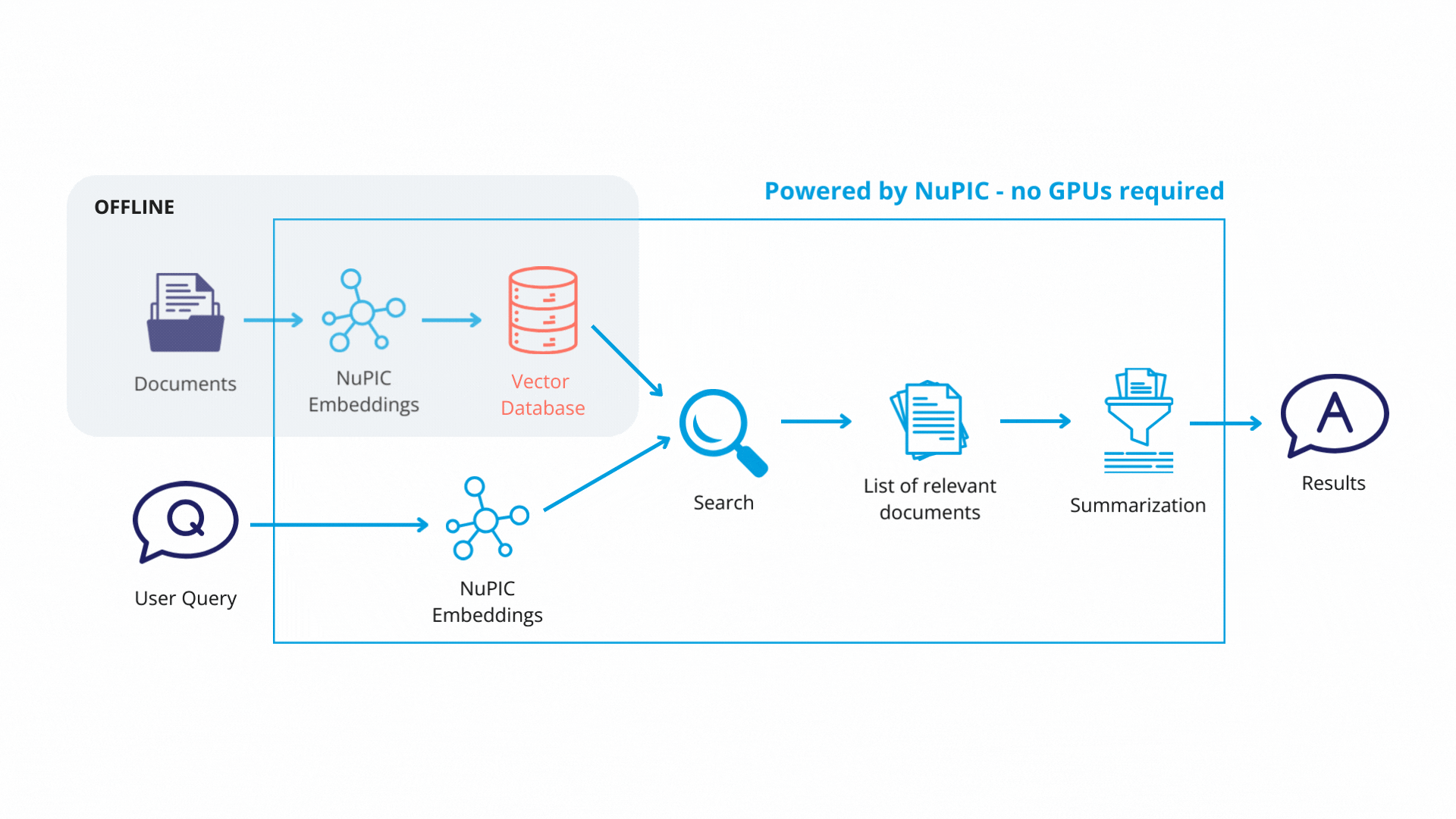
Using LangChain, we define a retrieval system with some key components:
qa_with_sources_chain = RetrievalQA.from_chain_type(
llm=llm, --------------------------> GPT-style chat model to help synthesize the response
retriever=retriever, --------------> Retrieve from the vector database and the associated embedding model
callbacks=[handler],
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs,
)
Finally, with the retrieval system in place, queries get passed through the embedding model. The resulting embedding vectors are compared against the vector database, and similar database entries (text chunks) are returned. Now, rather than simply returning text chunks verbatim, we use a GPT model to synthesize the content of these chunks, contextualizing them with respect to the original query in order to return a coherent, reader-friendly response.
response = qa_with_sources_chain(
{
"query": "Why are Sparse distributed representations (SDRs) a "
"important part of the Thousand Brains theory?"
}
)
print(response["result"])
Updated about 1 year ago