Architecture Overview
NuPIC provides the quickest route to deploying production-ready Large Language Models on CPUs - no deep learning expertise required.
When you first start your project, you have the option to choose a model from our Model Library, to deploy to the Inference Server or fine-tune with the Training Module. You'll select the appropriate model variant and fine-tuning task depending on your specific use case.
NuPIC Architecture
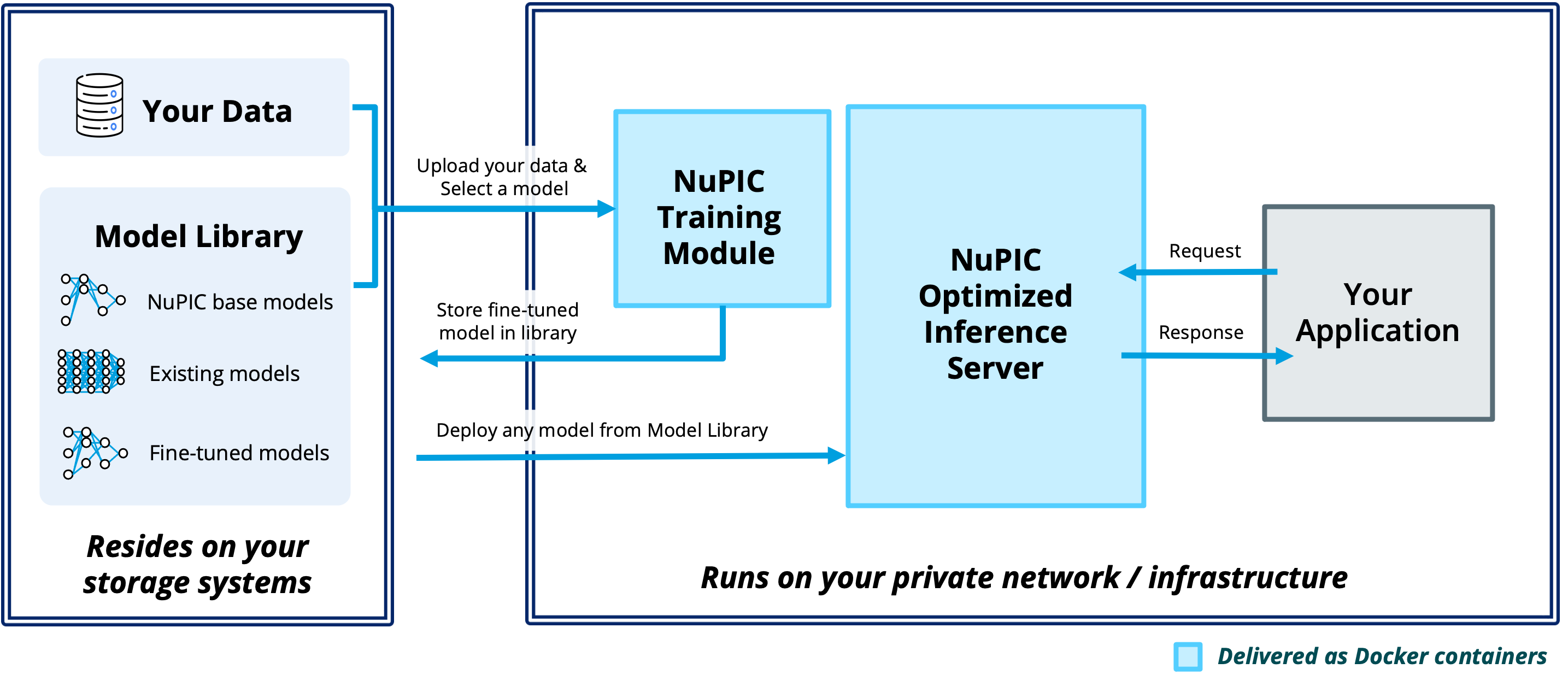
Model Library
The NuPIC Model Library includes pre-trained Large Language Models (LLMs) optimized for the inference of numerous NLP tasks. They offer an easy starting point for your AI projects, eliminating the time and complexity of training models from scratch.
From text classification to summarization, you can explore various models, each with different strengths and trade-offs, and choose the most suitable for your task. Leveraging these pre-trained models means you don’t have to start from scratch; pick a model and get started right away. The model library includes:
- NuPIC Optimized Models: Pre-trained and optimized for fast inference, these models are ready for immediate deployment on the NuPIC Inference Server.
- Fine-Tuned Models: Using the NuPIC Training Module, you can fine-tune the NuPIC optimized models on your data, and then easily deploy to the NuPIC Inference Server, allowing you to create highly specialized and accurate models tailored to your unique use case and datasets.
- Bring Your Own Model: Can't find what you need from the NuPIC optimized models? You can import supported model architectures into NuPIC. Imported models can be fine-tuned using the NuPIC Training Module too.
NuPIC Inference Server
The heart of NuPIC is our optimized inference server. This component contains our hand-optimized AMX code, and our optimized libraries for running transformer networks efficiently on CPUs. Because the Inference Server is CPU based, a single instance of the server can run dozens of different models in parallel. Each model runs in a separate process and is completely asynchronous. No batching or synchronization is required to achieve maximal throughput. In fact, you can mix and match different models within the same instance!
The NuPIC Inference Server uses industry standard protocols and includes a simple REST API for accessing models and performing inference. It is deployed using the industry standard Triton Inference Server, making NuPIC easy to integrate into almost any standard MLOps solution, such as Kubernetes. The Triton server supports HTTP and GRPC protocols, sync/async, streaming requests, and dynamic batching for deployed models.
Cajal Libraries
Within the NuPIC Inference Server is the NuPIC real-time engine, built using our internal Cajal libraries (named after the very first neuroscientist Santiago Ramón y Cajal). The Cajal libraries are written using a combination of C++ and assembler. They include an optimized runtime, custom ONNX routines, and a set of hardware optimizations that leverage SIMD instructions, specifically AVX2, AVX512, and AMX.

The design of Cajal enables NuPIC to realize unparalleled throughput. Cajal attempts to minimize data movement and memory bandwidth. Memory management routines maximize the use of L1 and L2 cache and share memory between models as appropriate. Internally, our AMX codebase uses the bf16 format which optimizes the bandwidth required for matrix calculations without compromising accuracy, a common problem with more aggressive quantization and lower precision formats. No specific quantization step is required to use models within NuPIC.
NuPIC Training Module
The NuPIC Training Module enables you to improve the accuracy of your models using your data. You can choose one of the base models in the model library (or import your own), upload your data to the training module, and fine-tune the model based on your data. This makes the model more specific to your application and typically improves accuracy significantly. The fine-tuned models are then stored back into the library. Any model, including the NuPIC base models, and the fine-tuned models can be easily deployed using the NuPIC Inference Server.
The Training Module is provided as a docker container and has a simple REST API to allow easy integration into your existing infrastructure. A command line client is also provided to allow training without writing a single line of code!
Delivered via Docker
NuPIC components are delivered as Docker containers. You can install the inference server and training module in your infrastructure, private cloud, or even on your laptop. NuPIC runs completely within your private network and corporate infrastructure. Your data and the models reside completely on your private storage systems. You have complete control over the models, when they are updated, your data, and data governance policies.
Python Client
You don't need to be a C++ whiz to use NuPIC. We provide Python clients that integrate directly with your app, and handle interactions with the Inference Server and Training Module.
Example Code
We provide Python-based example code demonstrating how to leverage our product's features. Some examples may require fine-tuning, while others can be deployed immediately to our Inference Server without any fine-tuning.
Updated 2 days ago