Prompt Engineering
GPT models, including those in NuPIC, take natural language texts from the user as input. These textual inputs are known as prompts.
You can think of GPT models as advanced versions of the next-word prediction models on your smartphone keyboard. On such a keyboard, the predicted next word is dependent on the words you previously typed. Similarly, outputs from GPT models are heavily dependent on the style, format and content of input prompts.
Prompt engineering refers to the strategies used in writing prompts that yield the desired output from GPT models. This can help encourage more specific outputs from a GPT model, such as encouraging it to stay on-topic, preventing excessively verbose outputs, returning outputs in a structured text format (e.g., JSON), etc.
Prompt engineering is a trial-and-error process that requires extensive experimentation. Moreover, different GPT models respond differently to prompts. Unsurprisingly, prompt engineering is a huge topic, so this page aims to provide a primer to help you get started. Let's go!
Basic Principles
Write Clearly and Explicitly
GPT models can't read our minds (at least not yet!), so we have to be explicit about exactly what we need from them. This includes specifying how long you want the output to be. Here's an example of a vague prompt:
Who is the leader of France?Here's a much better one:
Who was the president of France in May 1998? Respond concisely in 20 words or less.Take on a Persona
Does the model sound a little too cold for a customer-facing role? You can simply ask the model to take on a suitable persona. For example:
You are a friendly pirate who provides directions to visitors at an amusement park.Need your GPT model to help with coding problems?
You are an expert Python programmer. I want you to provide a solution to this problem:Delimit Quotes and Code Snippets
It helps to clearly mark out additional reference texts in your prompt, so the model "knows" exactly what to focus on. For example:
Summarize the text below in 20 words, denoted between triple backticks:
```
Numenta technology is based on two decades of neuroscience research and
breakthrough advances in understanding what the neocortex does and how
it does it. We have developed a framework of intelligence called** the
Thousand Brains Theory**, which suggests mechanisms for how the brain
efficiently represents information, learns about the structure of the
world, and makes predictions. This research enabled us to develop unique
brain-based architecture, data structures, and algorithms that
dramatically increase performance in today's AI systems and unlock new
capabilities in AI.
```Other common delimiters include triple quotes """ and dashes ---.
Keep It Simple, Silly!
GPT models are unlikely to give you the result you want if you specify an overly complex task. Here's an example:
Give me instructions for building an autonomous vehicle.You could instead split this into separate prompts, starting with a prompt to ask the model to help you break it down:
What are the main engineering systems within an autonomous vehicle?What kind of sensor modules do I need?What are the geolocation systems that I could use?Admitting "I Don't Know"
Despite sounding absolutely confident, GPT models are not all-knowing oracles. While they typically incorporate vast amounts of knowledge based on their pretraining data, these data are limited to certain cutoff dates.
Prompting the model about things it doesn't actually have knowledge of is likely to result in the model making up answers, aka "hallucinations", so we want to avoid these prompts.
An additional safeguard is to explicitly prompt the model to say "I don't know":
You are a helpful AI assistant that provides accurate information about feline care.
If asked about propagation tips for Borneon karst mosses, respond with "I don't know".In addition, highly specialized/technical knowledge domains are underrepresented in pretraining data, so expect the model to be less knowledgeable/reliable on these topics. In these cases, consider using retrieval-augmented generation.
Advanced Prompt Engineering
These prompt engineering techniques build on top of the basic principles we covered above. However, these techniques involve longer prompts, which means the model will take longer to respond. Ultimately, it's a balancing act between accuracy and performance.
Few-Shot Prompting
Do you need a very specific output format, but the model is just not nailing it? This is where few-shot prompting can come in handy. This technique leverages the ability of GPT models to learn from just a few examples provided in the prompt (aka in-context learning).
Here's an example: suppose you want to convert CSV data to JSON format. The JSON format has strict formatting requirements (e.g., nesting, double quotes). Small mistakes in JSONs produced by GPT models can lead to downstream ingestion errors. A few-shot prompt containing input and output examples can help mitigate this.
Convert the provided CSVs to JSONs. Adhere strictly to the following examples delineated between
triple backticks:
CSV input 1:
```
Column1,Column2,Column3
🌟Sparkle1🌟,🍀Lucky1🍀,🔥Fire1🔥
✨Shimmer2✨,🌈Rainbow2🌈,💧Water2💧
```
JSON output 1:
```
[
{
"Column1": "🌟Sparkle1🌟",
"Column2": "🍀Lucky1🍀",
"Column3": "🔥Fire1🔥"
},
{
"Column1": "✨Shimmer2✨",
"Column2": "🌈Rainbow2🌈",
"Column3": "💧Water2💧"
}
]
```
CSV input 2:
```
[
{
"Column1": "🎩Hat1🎩",
"Column2": "🎸Guitar1🎸",
"Column3": "🎨Art1🎨"
},
{
"Column1": "🕶️Shades2🕶️",
"Column2": "🎷Sax2🎷",
"Column3": "📚Book2📚"
}
]
```
JSON output 2:
```
[
{
"Column1": "🎩Hat1🎩",
"Column2": "🎸Guitar1🎸",
"Column3": "🎨Art1🎨"
},
{
"Column1": "🕶️Shades2🕶️",
"Column2": "🎷Sax2🎷",
"Column3": "📚Book2📚"
}
]
```
CSV input 3:
```
Column1,Column2,Column3
🦄Unicorn1🦄,🌍Earth1🌍,⚡Thunder1⚡
🐉Dragon2🐉,🌌Galaxy2🌌,🌟Starlight2🌟
```
JSON output 3:Here we provided two input-output example pairs. The actual input goes under CSV input 3, and we end off with JSON output 3: to encourage the model to continue in the same format seen in earlier examples.
Chain-Of-Thought
For complex problems, you can encourage the GPT model to reason step-by-step. In doing so, outputs for each step can inform the subsequently generated text. By conditioning each reasoning step, the overall effect is that the model is more likely to arrive at the correct answer. This is particularly useful for logic or math problems, which GPT models otherwise struggle with (since they are language models).
Help me with the following math problem, delineated between triple backticks.
I want you to show your reasons step-by-step.
```
A farmer has a rectangular field that measures 120 meters in length and 80 meters
in width. He wants to build a fence around the field and then divide the field
into two equal parts by adding another fence parallel to the shorter side. How
much fencing does the farmer need in total?
```Expected output:
1. Understanding the problem: The farmer needs to build a fence around the entire field
and then add another fence to divide the field into two equal parts parallel to the shorter side.
2. Calculate the perimeter of the rectangular field:
• The perimeter (P) of a rectangle is given by the formula P = 2 \times (length + width) .
• Substitute the given values: P = 2 \times (120 \, \text{m} + 80 \, \text{m}) .
• Perform the calculation: P = 2 \times 200 \, \text{m} = 400 \, \text{m} .
• So, the perimeter of the field is 400 meters.
3. Calculate the length of the dividing fence:
• The field is divided into two equal parts parallel to the shorter side (width),
so the dividing fence will be the same length as the shorter side (width).
• The length of the dividing fence is 80 meters.
4. Calculate the total amount of fencing needed:
• Add the perimeter of the field and the length of the dividing fence.
• Total fencing needed = Perimeter of the field + Length of the dividing fence.
• Substitute the calculated values: Total fencing needed = 400 , \text{m} + 80 , \text{m}.
• Perform the calculation: Total fencing needed = 480 , \text{m}.
5. Conclusion: The farmer needs 480 meters of fencing in total.Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) is helpful when you need the GPT model to answer questions about highly specific information that is unlikely to have been represented in its pre-training data. Examples include product documentation, customer databases, technical papers.
RAG involves using a non-generative embedding model to convert the user's question into a numerical vector for searching against a database (retrieval). Retrieved database entries are then passed to the GPT model, which synthesizes an easy-to-read answer.
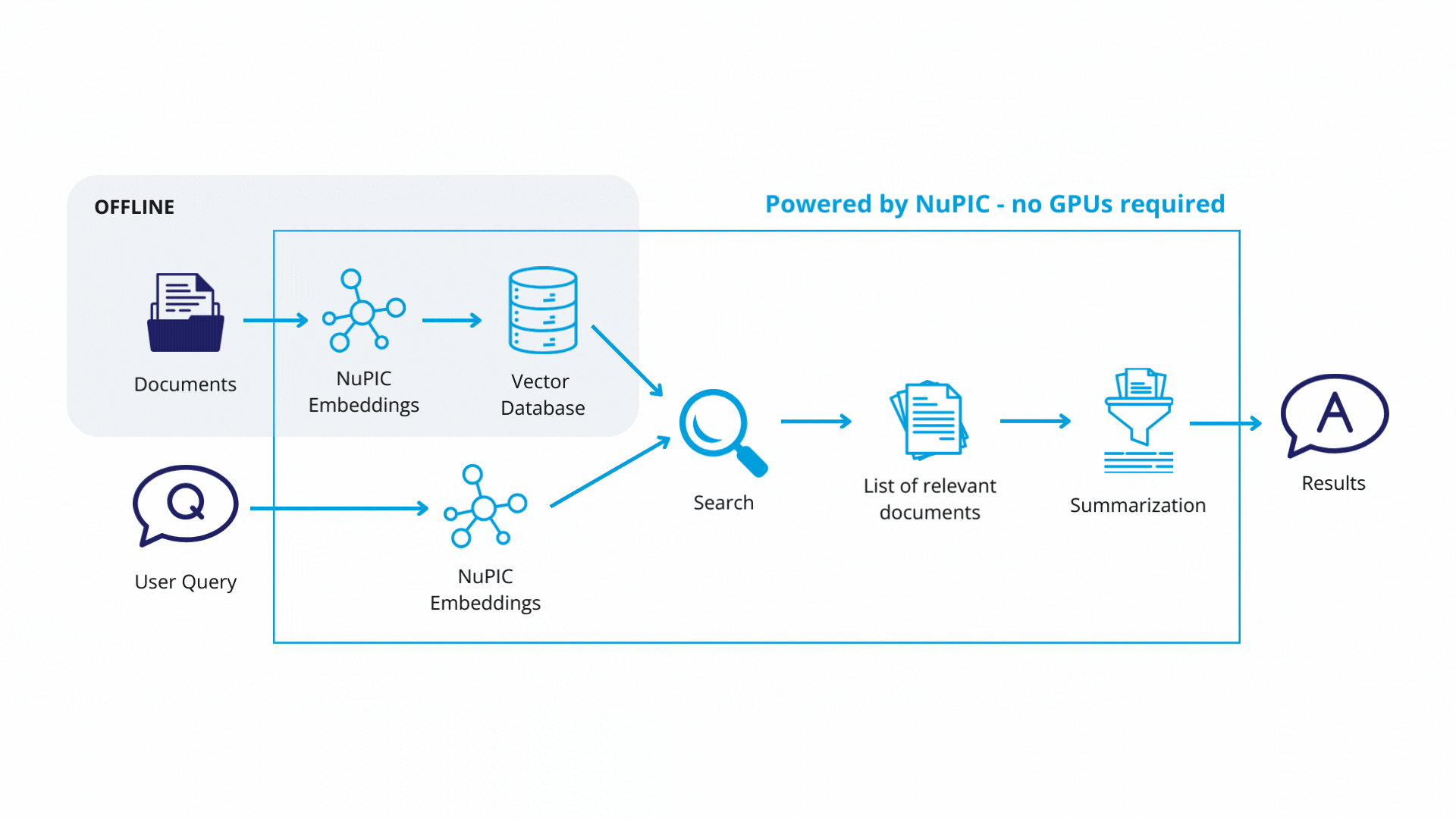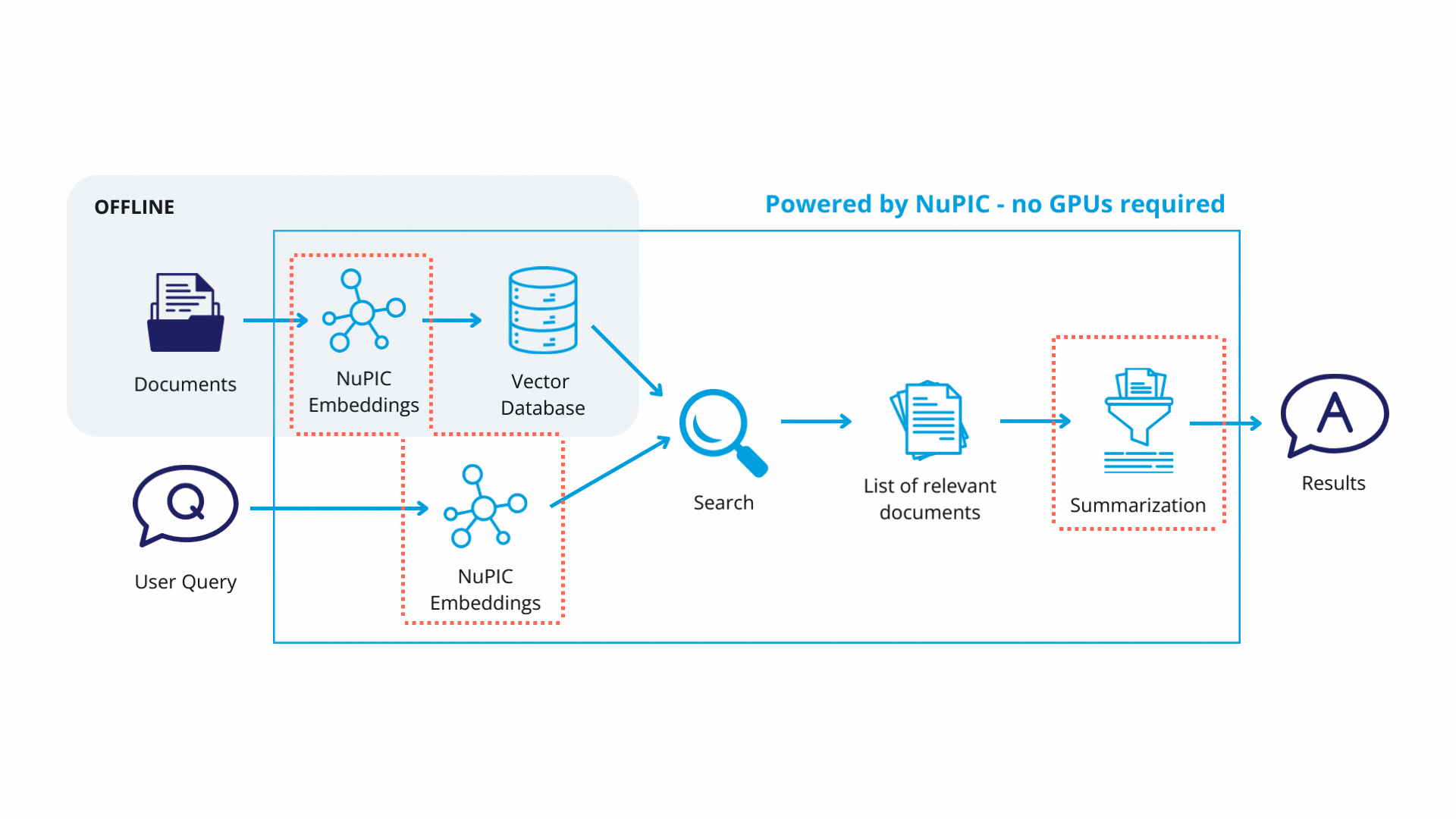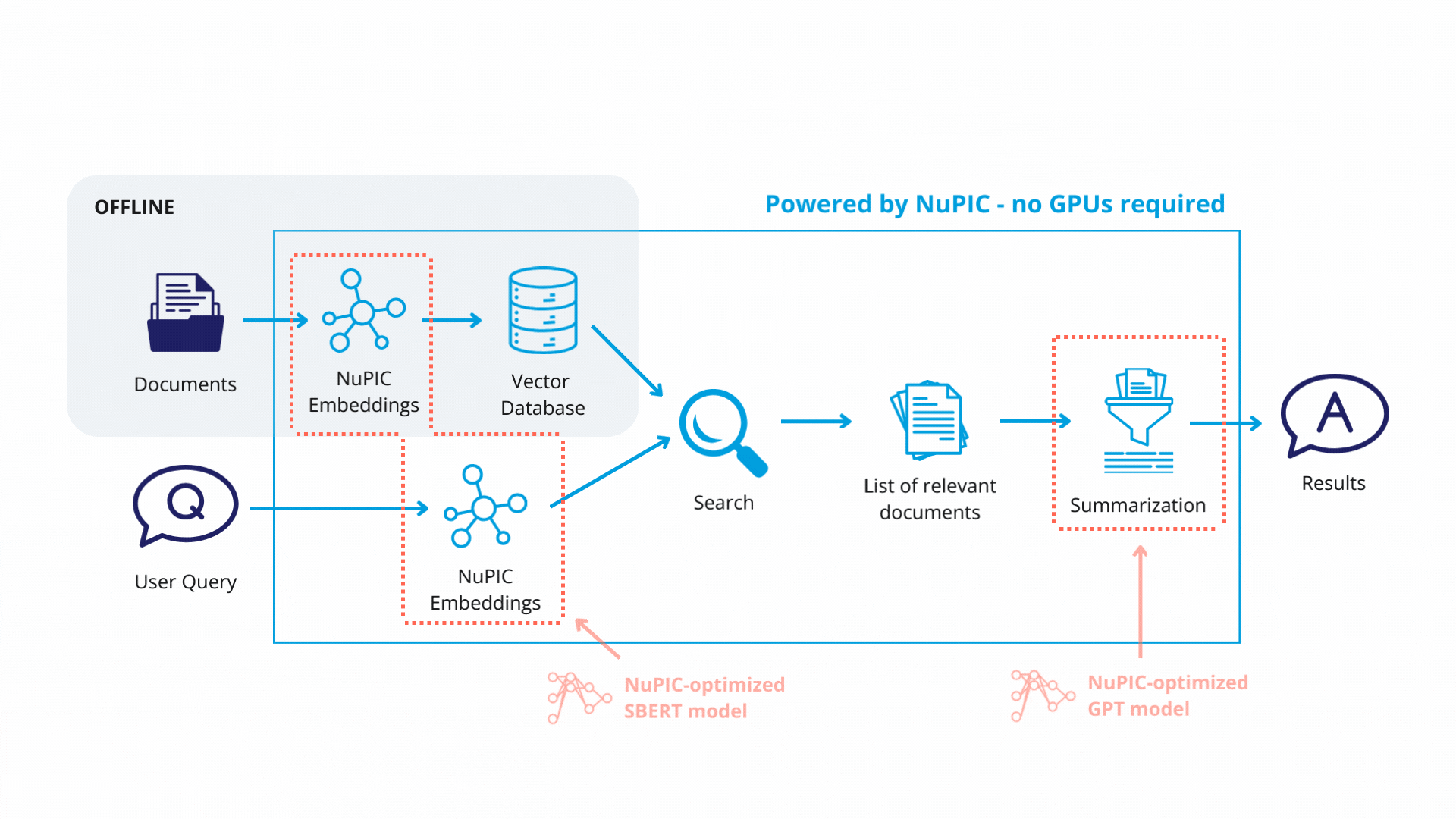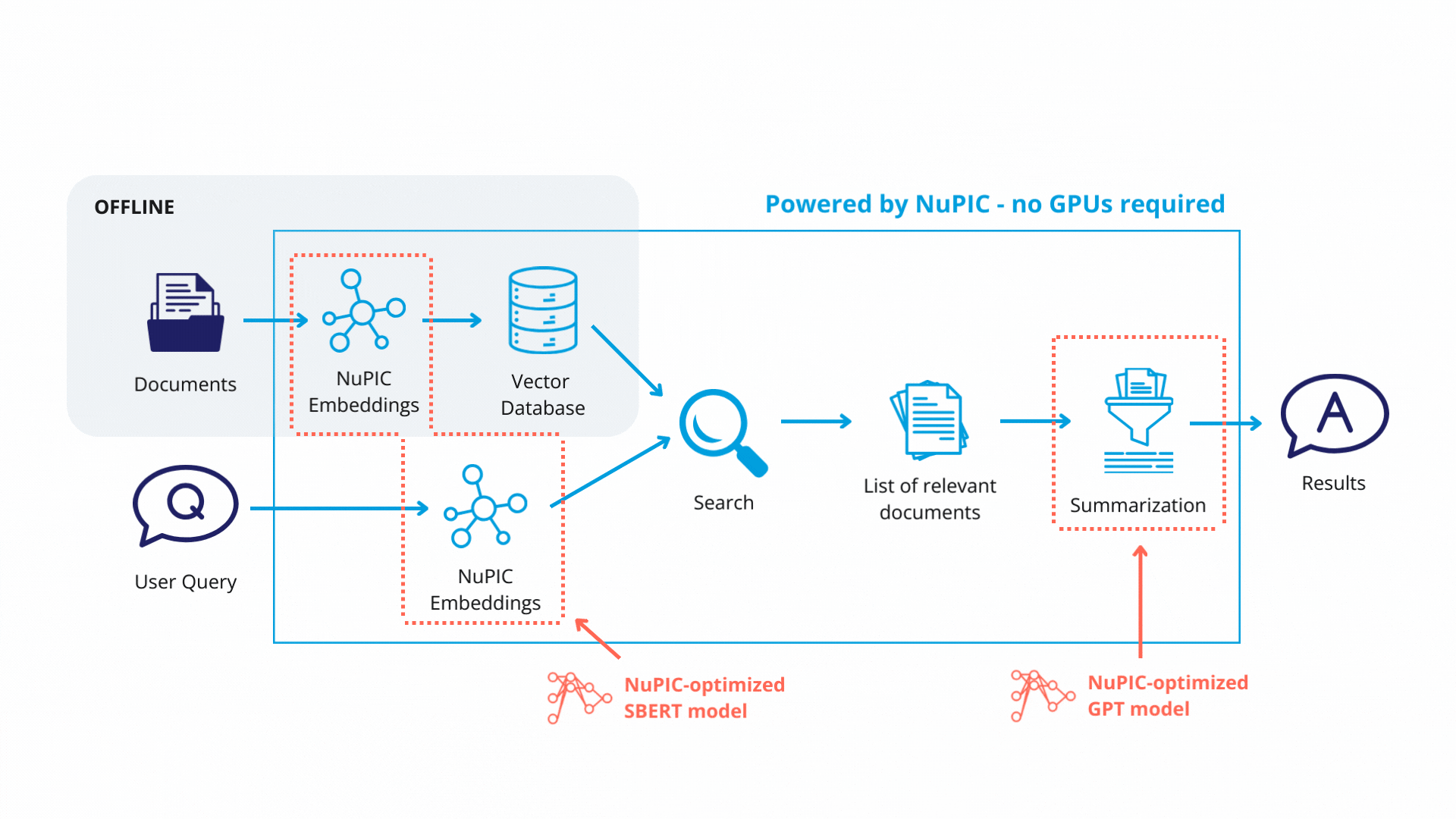
The prompt for a RAG system might look like this:
Use the context to answer please. If the answer to the question is not provided
in the document, please answer the question by using your own knowledge about
the topic but please don't forget to let the user know that the response was
generated by you instead of using the document. Always answer the question.
Context:
```
{context}
```
Question:
```
{question}
```
Answer:The {context} and {question} placeholders are intended to be programmatically filled in with retrieved documents and user queries, respectively.
NuPIC includes LangChain integrations to help you quickly get started with RAG. You can refer to our tutorial here.
Is prompt engineering still not getting the outputs you want?
You might consider fine-tuning your GPT model. Check out a tutorial here!
Additional Resources
If you'd like to learn more, we've also linked a few additional external resources for your reading pleasure:
Updated 7 days ago