Run Multiple Models Concurrently
Multi-Tenancy
NuPIC Inference Server has the capability to simultaneously host and execute multiple heterogeneous models, thanks for the ability to run inferences on CPUs. This enables a single server instance to serve a variety of models, which can differ in their architecture, size, and computational requirements, without the need for dedicating separate resources to each model. We call this "model multi-tenancy".
The advantages of model multi-tenancy are manifold. Firstly, it significantly enhances resource utilization by ensuring that the computational resources are efficiently used across all deployed models. This leads to cost savings, as it reduces the need for multiple dedicated servers. Secondly, it simplifies management and operational overhead since deploying, monitoring, and updating a multitude of models can be handled within a single infrastructure. Lastly, it increases flexibility and scalability, allowing for the easy addition or removal of models based on changing requirements or demand.
NuPIC's users get model multi-tenancy out of box without any additional work. Users can configure the number of concurrently running instances for each model by adjusting instance_group.count property in the configuration file. Different models can be loaded and executed on CPUs.
The chart below shows the results of running 128 independent NuPIC-optimized BERT-Large models on the NuPIC Inference Server, showing its ability to scale efficiently while handling multiple different models simultaneously:
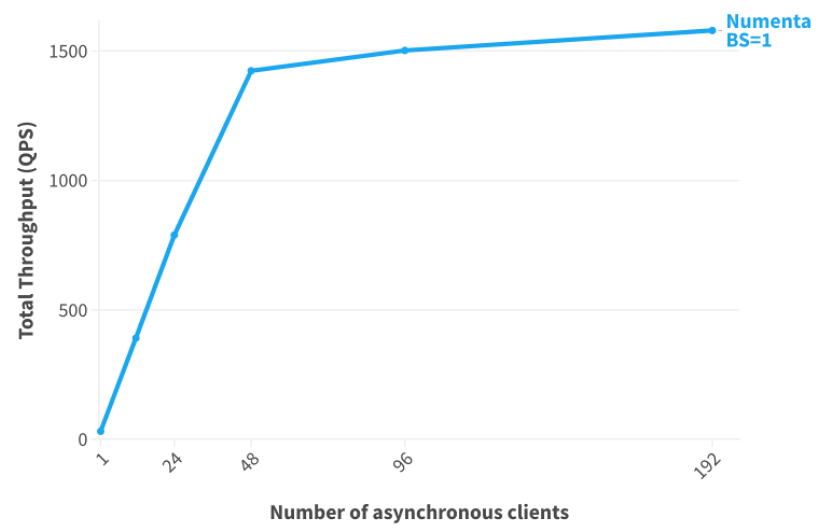
The total throughput of 128 independent NuPIC-optimized BERT-Large models with an increasing number of asynchronous clients
Adjusting Shared Memory
Running multiple models concurrently will require more compute resources, including the shared memory memory (/dev/shm) allocated to each container. By default, each instance of the Inference Server 512MB is allocated 512MB. To increase this, you will have to edit this in nupic/nupic_inference.sh:
docker run --detach \
${CPUSET} \
--name ${CONTAINER_NAME} \
--volume ${NUMENTA_VOLUME}:${IS_DIR} \
--volume ${NUMENTA_VOLUME}/models:${MODELS_DIR} \
--env CAJAL_LICENSE_FILE=${CAJAL_LICENSE_FILE} \
--env CAJAL_NUM_THREADS=0 \
--publish ${EXPOSE_PORT} \
--publish ${METRICS_PORT} \
--cap-add SYS_NICE \
--shm-size=512m \ <---------------------------
${GPUARGS} \
${DOCKER_IMAGE} \
/bin/bash ${SCRIPTS_DIR}/triton.sh
Please see the official Docker documentation for the notation required for this parameter.
Updated 9 days ago