Installation: Inference Server and Training Module
This page covers the installation of the Inference Server and Training Module. Please visit this page for instructions on installing the Python clients.
Installation Options
As explained in our Architecture Overview, NuPIC consists of the Inference Server and Training Module. You can interact with these containers using our Python clients, or alternatively via a REST API (contact us) for help with this).
Option 1: Installing on the same Linux machine
To get started, we recommend installing the Inference Server, Training Module and Python clients on the same Linux machine. This is the fastest and easiest way to set up NuPIC, especially for evaluation or development purposes.
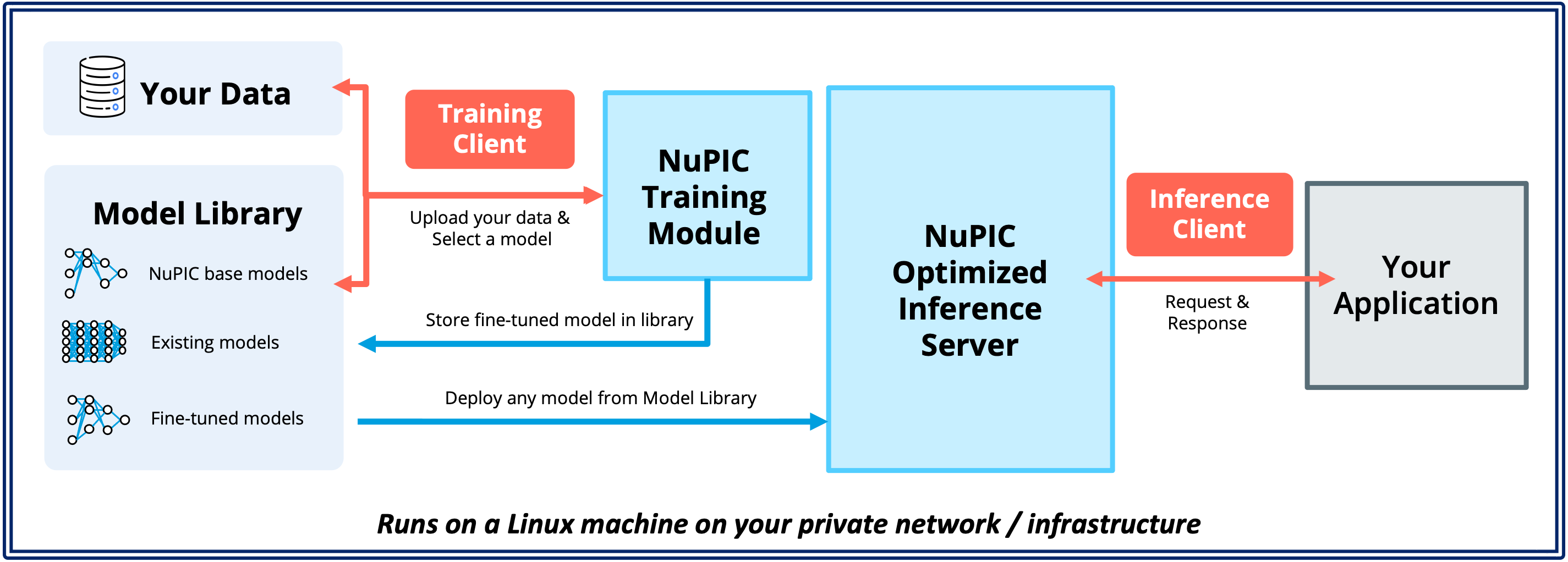
Option 2: Installing on your cloud or on-premise infrastructure
Alternatively, you can also install the Inference Server and Training Module on your cloud or on-premise Linux infrastructure. In this setup, the Python clients are installed on the end user's laptop or desktop. This setup is useful when your use case involves a decentralized pool of users sending requests to shared infrastructure for their inference and/or training needs.
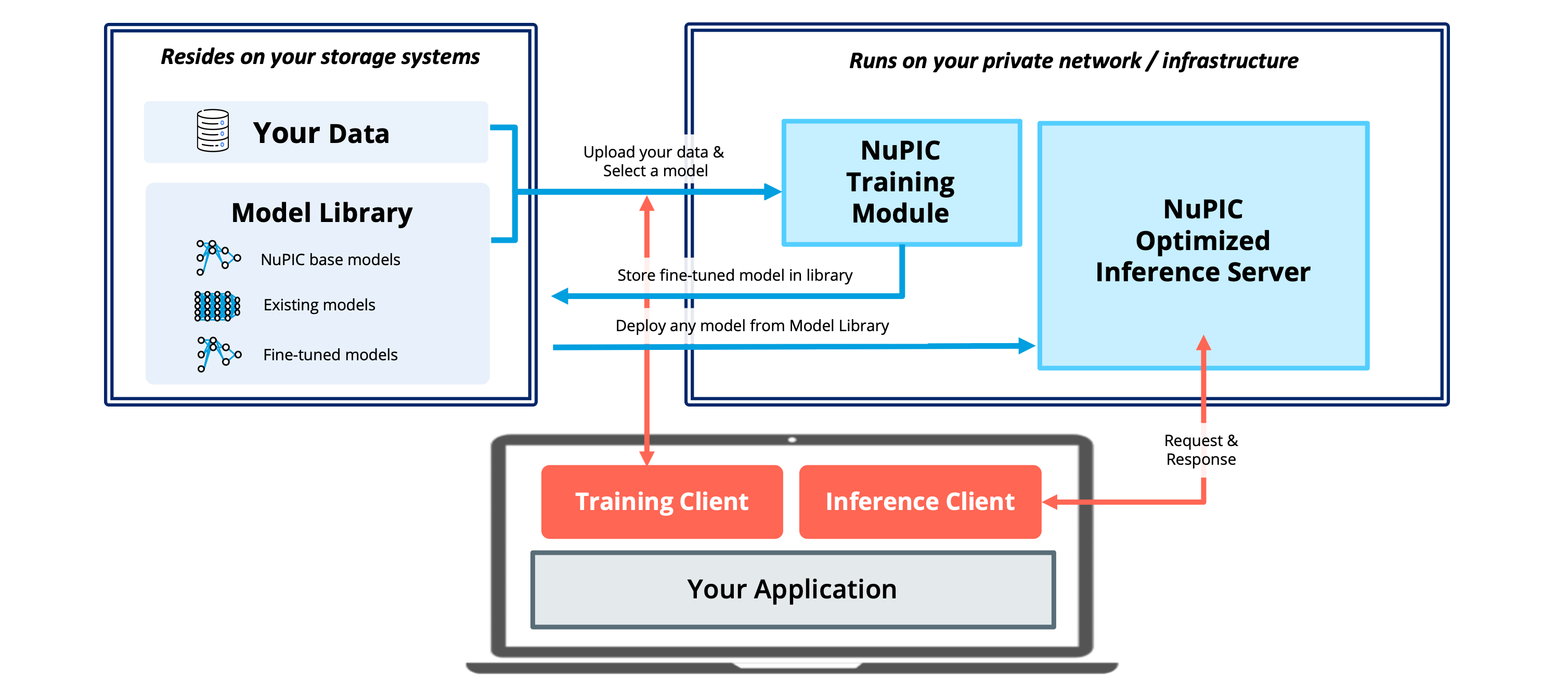
You may also consider running the Inference Server and Training Module on separate machines that are optimized for the respective workloads. For instance, the Inference Server could be hosted on a machine with AMX-enabled CPUs for the best inference performance. The Training Module could then be hosted on a separate GPU-enabled machine. Alternatively, in the case where there is a need to transfer large model files between the Training Module and Inference Server, it may be more advantageous to host both components on a single machine.
Obtain a NuPIC license
Please contact Numenta to obtain an evaluation or production license. Upon extracting the provided zip file, you will see the following directory structure.
nupic
├── install.sh -------------> Installation script
├── license.cfg ------------> License information
├── license.sig ------------> License file
└── nupic.examples/ --------> Python clients and use-case examplesInstallation
Navigate to the nupic/ directory, make install.sh executable, and proceed to execute it:
cd your_path/nupic
chmod +x install.sh
./install.shThe installation script downloads and extract the Inference Server and Training Module container, as well as the weights of our optimized models.
After installation, your folder should look like this:
nupic/
├── downloads/
├── inference/
├── install.sh
├── license.cfg
├── license.sig
├── nupic.examples/
├── nupic_inference.sh
├── nupic_training.sh
└── training/Launching the Inference Server
Make the Inference Server executable, and then launch it:
chmod +x nupic_inference.sh
./nupic_inference.sh --startdocker psYou should see something similar to the following:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5d9a4a8eba9d nvcr.io/nvidia/tritonserver:23.06-py3 "/opt/nvidia/nvidia_…" 2 seconds ago Up 1 second 127.0.0.1:8000->8000/tcp, 127.0.0.1:8002->8002/tcp nupic_inference_serverThe inference server is now ready for use! By default, the docker container will run the Inference Server on port 8000 (Installation Option 1). You can access it locally via http://localhost:8000.
Permissions error?
Did you encounter a
permission deniederror when trying to start the inference server? Make sure you've followed the post-installation steps for Docker (remember to reboot your machine!). Another way is to run Inference Server, Training Module and Docker-related commands with root permissions by addingsudoat the front of your commands.
Alternatively, if you intend to access the Inference Server from a remote Python client (Installation Option 2), you should replace localhost with your host machine's IP address. This might be a dynamic IP address assigned by your cloud service provider, or a static IP address that you have otherwise assigned through your cloud service provider, load balancer and/or network administrator. Do also ensure that your network security policy allows the Inference Server IP and ports to be accessible by remote clients, and vice versa. With these in place, you can start the Inference Server with additional flags to expose the server's ports to remote clients:
./nupic_inference.sh --start --expose --expose-metricsWhen accessing from a remote client, you will also have to configure the Python inference and training clients to access the correct IP address.
Launching the Training Module
The Training Module can be launched in a similar manner:
chmod +x nupic_training.sh
./nupic_training.sh --startTo verify that the training module has launched:
docker psYou should see the following output:
dde495f69600 nupic_training_module:1.1.2 "/opt/nvidia/nvidia_…" About a minute ago Up 57 seconds 0.0.0.0:8321->80/tcp, :::8321->80/tcp nupic_training_moduleCongrats, the training module is ready for use! By default, the docker container will run the Training Module locally on port 8321 (Installation Option 1). You can access it via http://localhost:8321.
Alternatively, if you intend access the Training Module from a remote Python client (Installation Option 2), you should replace localhost with your host machine's IP address. Remember, when accessing from a remote client, you will also have to configure the Python client to access the correct IP address.
Shutting Down
To shut down the Inference Server and Training Module, run the same scripts with the --stop flag.
./nupic_inference.sh --stop
./nupic_training.sh --stopRun docker ps to verify that the containers are no longer running.
Updated 9 days ago